Практическое руководство: предсказать отток клиентов
Перевод
Ссылка на автора
Короче говоря — в этой статье мы хотим испачкать руки: создать модель, которая идентифицирует наших любимых клиентов с намерением покинуть нас в ближайшем будущем. Мы делаем это путем реализации прогностической модели с помощью python. Не ожидайте идеальной модели, но ожидайте чего-то, что вы можете использовать в своей собственной компании / проекте сегодня!

Прежде чем мы начнем, давайте кратко напомним, что такое отток на самом деле: «Отток» определяет количество клиентов, которые отписались или аннулировали свой контракт на обслуживание. Клиенты, отворачивающиеся от ваших услуг или продуктов, не приносят удовольствия любому бизнесу. Очень дорого отыграть их, когда они проиграли, даже не думая, что они не сделают все от них зависящее, если не будут удовлетворены. Узнайте все об основах оттока клиентов в одной из моих предыдущих статей, Теперь давайте начнем!
Как мы прогнозируем отток клиентов?
Основной слой для прогнозирования оттока клиентов в будущем — это данные из прошлого. Мы смотрим на данные от клиентов, которые уже произвели отток (ответ) и их характеристики / поведение (предикторы) до того, как отток произошел. Подбирая статистическую модель, которая связывает предикторы с ответом, мы попытаемся предсказать ответ для существующих клиентов. Этот метод относится к категории контролируемого обучения, на случай, если вам понадобится еще одно жужжащее выражение. На практике мы делаем следующие шаги, чтобы сделать эти точные прогнозы:

- Вариант использования / бизнес-кейс
Первый шаг — это понимание бизнеса или варианта использования с желаемым результатом. Только понимая конечную цель, мы можем построить модель, которая действительно полезна. В нашем случае цель состоит в том, чтобы уменьшить отток клиентов, заранее определив потенциальных кандидатов на отток, и предпринять активные действия, чтобы заставить их остаться. - Сбор и очистка данных
Понимая контекст, можно определить правильные источники данных, очистить наборы данных и подготовиться к выбору функций или разработке. Звучит довольно просто, но это, вероятно, самая сложная часть. Модель прогнозирования хороша только как источник данных. И особенно у стартапов или небольших компаний часто возникают проблемы с поиском достаточного количества данных для адекватного обучения модели. - Выбор функций и инжиниринг
На третьем этапе мы решаем, какие функции мы хотим включить в нашу модель, и подготавливаем очищенные данные для использования в алгоритме машинного обучения для прогнозирования оттока клиентов. - моделирование
С подготовленными данными мы готовы кормить нашу модель. Но чтобы делать хорошие прогнозы, нам, во-первых, нужно найти правильную модель (выбор), а во-вторых, оценить, что алгоритм действительно работает. Хотя обычно это занимает несколько итераций, мы будем делать это довольно просто и остановимся, как только результаты будут соответствовать нашим потребностям. - Идеи и действия
И последнее, но не менее важное: мы должны оценивать и интерпретировать результаты. Что это значит и какие действия мы можем извлечь из результатов? Поскольку прогнозирование оттока клиентов — это только половина дела, и многие люди забывают, что, просто прогнозируя, они все равно могут уйти. В нашем случае мы действительно хотим, чтобы они перестали уходить.
Инструменты, которые мы используем

Чтобы предсказать, изменится ли клиент или нет, мы работаем с Python и его удивительными библиотеками с открытым исходным кодом. Прежде всего мы используем Jupyter Notebook, приложение с открытым исходным кодом для живого программирования, которое позволяет нам рассказать историю с помощью кода. Кроме того, мы импортируем Панды, который помещает наши данные в простую в использовании структуру для анализа данных и преобразования данных. Чтобы сделать исследование данных более понятным, мы используем plotly визуализировать некоторые из наших идей. Наконец с scikit учиться мы разделим наш набор данных и обучим нашу прогнозную модель.
Набор данных
Одним из наиболее ценных активов компании являются данные. Поскольку данные редко публикуются, мы берем доступный набор данных, который вы можете найти на IBMs веб-сайт, а также на других страницах, таких как Kaggle: Набор данных клиентов Telcom. Набор необработанных данных содержит более 7000 записей. Все записи имеют несколько функций и, конечно, столбец с указанием, изменился ли клиент.
Чтобы лучше понять данные, мы сначала загрузим их в панды и исследуем их с помощью некоторых очень простых команд.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")from pylab import rcParams%matplotlib inline# Loading the CSV with pandas
data = pd.read_csv('..Customer Churn/Telco-Customer-Churn.csv')
Исследование и выбор функций
Этот раздел довольно короткий, так как вы можете узнать больше об общих исследованиях данных в лучших руководствах. Тем не менее, чтобы получить первоначальное представление и узнать, какую историю вы можете рассказать с помощью данных, исследование данных имеет определенный смысл. Используя функции python data.head (5) и «data.shape», мы получаем общий обзор набора данных.

Подробно мы рассмотрим целевую особенность, фактический «отток». Поэтому мы строим его соответственно и видим, что 26,5% от общего объема оттока клиентов Это важно знать, поэтому в наших данных об обучении мы имеем одинаковую долю клиентов с постоянным числом клиентов и клиентов с нулевым уровнем

# Data to plot
sizes = data['Churn'].value_counts(sort = True)
colors = ["grey","purple"]
rcParams['figure.figsize'] = 5,5# Plot
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=270,)plt.title('Percentage of Churn in Dataset')
plt.show()
Подготовка данных и разработка функций
Помните, что чем лучше мы подготовим наши данные для модели машинного обучения, тем лучше будет наш прогноз. У нас может быть самый продвинутый алгоритм, но если наши тренировочные данные отстой, наш результат тоже будет отстой. По этой причине ученые-данные тратят так много времени на подготовку данных. А так как предварительная обработка данных занимает много времени, но здесь это не главное, мы проведем несколько примерных преобразований.
- Удаление неактуальных данных
Там могут быть данные, которые не нужны для улучшения наших результатов. Лучше всего это определить с помощью логического мышления или создания корреляционной матрицы. В этом наборе данных у нас есть, например, идентификатор клиента. Так как это не влияет на наш прогнозируемый результат, мы удаляем столбец с помощью функции «drop ()» для панд.
data.drop(['customerID'], axis=1, inplace=True)
2. Недостающие ценности
Кроме того, важно обрабатывать недостающие данные. Значения могут быть определены, например, функцией «.isnull ()» в пандах. После определения нулевых значений это зависит от каждого случая, имеет ли смысл заполнить пропущенное значение, например, средним значением, медианой или режимом, или если имеется достаточно обучающих данных, полностью отбросить запись. В наборе данных, с которым мы работаем, есть очень необычный случай — нулевые значения отсутствуют. Нам повезло на сегодня, но важно знать, что обычно мы должны справиться с этим.
3. Преобразование числовых признаков из объекта
Из нашего исследования данных (в данном случае «data.dtypes ()») мы видим, что столбцы MonthlyCharges и TotalCharges являются числами, но на самом деле в формате объекта. Почему это плохо? Наша модель машинного обучения может работать только с фактическими числовыми данными. Поэтому с помощью функции «to_numeric» мы можем изменить формат и подготовить данные для нашей модели машинного обучения.
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'])
4. Категориальные данные в числовые данные
Поскольку мы не можем ничего вычислить со строковыми значениями, мы должны преобразовать эти значения в числовые. Простой пример в наборе данных Telcom — это пол. Используя функцию Pandas «get_dummies ()», два столбца заменят гендерный столбец на «гендерный_мале» и «гендерный_мале».

Кроме того, мы могли бы использовать функцию «get_dummies ()» для всех категориальных переменных в наборе данных. Это мощная функция, но может быть неприятно иметь так много дополнительных столбцов.
5. Разделение набора данных
Во-первых, наша модель должна быть обучена, во-вторых, наша модель должна быть протестирована. Поэтому лучше иметь два разных набора данных. На данный момент у нас есть только один, очень распространено разделить данные соответственно. X — данные с независимыми переменными, Y — данные с зависимой переменной. Переменная размера теста определяет, в каком соотношении данные будут разделены. Довольно часто это делается в соотношении 80 тренировок / 20 тестов.
data["Churn"] = data["Churn"].astype(int)Y = data["Churn"].values
X = data.drop(labels = ["Churn"],axis = 1)# Create Train & Test Data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
Логистическая регрессия и тестирование моделей
Логистическая регрессия является одним из наиболее часто используемых алгоритмов машинного обучения, и в основном используется, когда зависимая переменная (здесь отток 1 или отток 0) является категориальной. Независимые переменные, напротив, могут быть категориальными или числовыми. Обратите внимание, что, конечно, имеет смысл детально понять теорию, лежащую в основе модели, но в этом случае наша цель состоит в том, чтобы использовать прогнозы, которые мы не пройдем через эту статью.
Шаг 1. Давайте импортируем модель, которую мы хотим использовать из sci-kit learn
Шаг 2. Делаем экземпляр модели
Шаг 3. Проводится ли обучение модели на основе набора обучающих данных и сохраняется ли информация, извлеченная из данных?
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
result = model.fit(X_train, y_train)
С обученной моделью мы можем теперь предсказать, изменился ли клиент для нашего тестового набора данных. Результаты сохраняются в «gnition_test », а затем измеряется и распечатывается оценка точности.
from sklearn import metrics
prediction_test = model.predict(X_test)# Print the prediction accuracy
print (metrics.accuracy_score(y_test, prediction_test))

Результаты показывают, что в 80% случаев наша модель предсказывала правильный результат для нашей проблемы бинарной классификации. Это считается очень хорошим для первого запуска, особенно когда мы смотрим, какое влияние оказывает каждая переменная и имеет ли это смысл. Таким образом, с конечной целью сократить отток и своевременно предпринять правильные предупреждающие действия, мы хотим знать, какие независимые переменные больше всего влияют на наш прогнозируемый результат. Поэтому мы устанавливаем коэффициенты в нашей модели на ноль и смотрим вес каждой переменной.
# To get the weights of all the variables
weights = pd.Series(model.coef_[0],
index=X.columns.values)
weights.sort_values(ascending = False)

Можно заметить, что некоторые переменные имеют положительное отношение к нашей предсказанной переменной, а некоторые имеют отрицательное отношение. Положительное значение оказывает положительное влияние на нашу прогнозируемую переменную. Хорошим примером является «Контракт-месяц-месяц»: положительное отношение к оттоку означает, что наличие такого типа контракта также увеличивает вероятность оттока клиента. С другой стороны, «Контракт_Два года» находится в крайне негативном отношении к прогнозируемой переменной, а это означает, что клиенты с таким типом контракта вряд ли будут набирать деньги. Но мы также видим, что некоторые переменные не имеют смысла в первом пункте. «Fiber_Optic» находится на верхней позиции с точки зрения положительного влияния на отток. Хотя мы ожидаем, что это заставит клиента остаться, поскольку он предоставляет ему быстрый интернет, наша модель говорит о другом. Здесь важно копать глубже и получить некоторый контекст для данных.
Да, мы сделали это — что дальше?

Один — поговори со своей командой.
Мы не только выяснили, какие клиенты, вероятно, будут выпускать, но также и какие функции оказывают наибольшее влияние на уход клиента. Поэтому настоятельно рекомендуется поделиться этими идеями с вашей командой по работе с клиентами и адаптировать их фокус. Только если команда знает, на что следует обратить особое внимание, она сможет направлять клиента к функциям, которые заставляют его / ее дольше оставаться на месте. Поговорите открыто, обсудите варианты и убедитесь, что вы понимаете весь контекст. Во многих случаях команда поддержки клиентов или службы поддержки может дать дополнительную качественную информацию, которая может подчеркнуть ваши выводы или полностью рассказать другую историю вашим результатам.
Два — Взаимодействие с клиентами, которые могут отменить,
Да, есть история, что вы должны позволить спящим собакам лгать. Но в случае потенциального оттока это чушь собачья. Быть спокойным и надеяться, что ваш клиент не уйдет, рано или поздно на 100% обернется. Вместо этого не пугайтесь, выходите на улицу и общайтесь со своими клиентами. Вариантов много, но самый лучший — самый очевидный: поговорите с ними.
Посмотрите на их профиль, определите характеристики и проанализируйте прошлые взаимодействия с вашим продуктом, а затем просто поговорите с ними. Попросите обратную связь, расскажите о последних разработках, которые могут быть интересны, или ознакомьте их с новыми функциями продукта. Подходите к клиентам, которые, скорее всего, произойдут, но убедитесь, что вы предлагаете подходящие вещи, которые могут соответствовать их индивидуальным потребностям. Это создаст ощущение понимания и привязывает их к вам и вашему бизнесу.
************************************************** ************
Статьи, связанные с этим:
Практическое руководство: настройка среды данных с помощью Docker
Устранение оттока — это Хакерство Роста 2.0
Вводить в заблуждение с данными и статистикой
************************************************** *************
Большая часть того, о чем я пишу, заставляет меня быть занятым нашим собственным стартапом investory.io,
Будем рады услышать ваш опыт
************************************************** ************
Home
Expert solutions
Term
Что будет целевой переменной (y) в задаче поиска уходящих от компании клиентов?
Click the card to flip 👆

Created by
AlexaGermer
Тест к экзамену
Terms in this set (104)
Что будет целевой переменной (y) в задаче поиска уходящих от компании клиентов?
Уход клиента
Вы хотите выявлять клиентов, которые, вероятно, перестанут пользоваться услугами компании в ближайшую неделю. Это задача:
Кластеризации (и скорее всего классификации тоже)
Вы хотите предсказать суммы, которые клиенты потратят на оплату трафика в разные месяцы, исходя из истории их предыдущего потребления. Это задача:
Регрессии
Какие типы машинного обучения выделяют?
Обучение с учителем, обучение с подкреплением, обучение без учителя
Что такое машинное обучение?
Процесс, в ходе которого алгоритм принимает на вход данные и учится находить в них закономерности
Задача — разбить пользователей интернет-магазина на группы, зная только информацию об
их покупках. Определите тип задачи машинного обучения?
Кластеризации
Какие типы признаков (Features) существуют(ML)?
Бинарный, номинальный, порядковый, количественный
Предварительная обработка данных включает в себя
Очистку данных, стандартизацию и нормализацию данных
Номинальная шкала — это шкала
— содержащая только две категории
Содержащая только категории, которые не могут упорядочиваться и категории, которые могут упорядочиваться
Определения дохода клиента банка является задачей
Классификации
Other sets by this creator
Test Executor: ВССТ-контрольная-2(v1)
3 terms
AlexaGermer
Неправильные глаголы
228 terms
AlexaGermer
Алгебра и геометрия
40 terms
AlexaGermer
Дискретная математика — Коллоквиум
31 terms
AlexaGermer
Вы любите своих клиентов. Они позволяют существовать вашему бизнесу. Вы хотите сохранить их и беспокоитесь, какие из них могут хитро оглядываться через плечо, думая, может быть ваши конкуренты лучше? Отток может произойти внезапно из-за любого количества потенциальных факторов, и клиенты вряд ли напишут вам письмо «Уважаем… ”, объясняющее, почему дело не в вас, а в них.
Существует множество методов подсчёта вероятности оттока на одного клиента — возможно, слишком много. Когда дело доходит только до измерения коэффициента удержания клиентов, есть десятки различных метрик, которые компании используют для анализа. Более того, простой поиск в Google может подсказать вам, что единственный способ предотвратить отток вашей компании — это создать свое собственное комплексное решение.
Тем не менее, есть способы прогнозировании оттока, без необходимости быть программистом высокого уровня. Возможность заставить данные работать на вас и успешно предотвращать отток клиентов может стать разницей между сохранением прибыльных клиентов и их потерей.
Что такое система прогноза оттока клиентов?
Система прогноза оттока использует большие данные для выявления клиентов, которые могут перестать пользоваться вашим сервисом или покупать ваш продукт регулярно. Такие системы используется большинством крупных SAAS компаний, для выявления наиболее подверженных риску оттока клиентов. Если система сделана хорошо, это приводит к большой выгоде для бизнеса, независимо от его размера.
Основы прогнозирования оттока
База данных клиента объединяется с алгоритмическими методами машинного обучения, которые оценивают вероятность оттока данного пользователя. Различные алгоритмы совместимы с прогнозированием оттока. Модель машинного обучения, наиболее ассоциируемая с этой практикой, — это модель Дерево принятия решений (т. е. “Случайный лес”), которая включает в себя предварительную обработку данных с последующим обучением и оценкой.
Компании со своей командой специалистов по Data Science, могут создать свое решение. Некоторые предпочитают такой подход, учитывая отсутствие отраслевого консенсуса, относительно наилучшего способа прогнозирования оттока.
Отток убивает компании; профилактика поддерживает их здоровье
Это одна из наиболее часто произносимых истин о ведении бизнеса, основанном на продажах лояльным клиентам, но стоит повторить: даже казалось бы, низкие показатели оттока могут остановить рост компании или полностью «убить» ее. Даже небольшое число, отток 1,0%, отток 2,5%, отток 5,0% все еще потенциально смертелен.
Давайте предположим, что у компании на графике ниже очень высокий уровень привлечения клиентов. Если она сохранит отток на уровне около 1,0%, его рост (на существующих и новых клиентах) будет достаточным, чтобы избежать последствий.
Если позволить ей увеличить отток выше этого уровня, то она, вероятно, обнаружит, что не сможет привлечь новых клиентов достаточно быстро, чтобы сохранить траекторию роста, даже если уровень привлечения клиентов останется прежним.
Мы можем видеть существенное снижение роста, которые сопровождаются более высоким оттоком, более полно проиллюстрированные на графике ниже. Полезно рассматривать отток напрямую с точки зрения дохода — если ваш ежемесячный отток клиентов составляет 5%, это означает потерю дохода на 5%. Ситуация значительно усугубится с течением времени и приведет к огромным потерям потенциальных доходов к концу года.
Если вы не примете мер против непроизвольного оттока, вы поставите под угрозу стабильность ваших денежных потоков.
Можно с уверенностью сказать, что предотвращение оттока должно быть приоритетом.
Профилактика начинается с прогнозирования.
Остановите клиентов, прежде чем они уйдут
При правильном использовании, прогнозирование оттока может стать важным преимуществом для более четкого представления об опыте ваших клиентов с вашим сервисом (продуктом).
Несмотря на т, что диапазон потенциальных факторов, вызывающих отток, может быть большим, остановка оттока часто связана с индивидуальным подходом к улучшению качества обслуживания клиентов. Система прогноза оттока дает вам возможность улучшить клиентский опыт, прежде чем они уйдут навсегда.
Получите представление о тенденциях оттока
Система прогноза оттока клиентов не только помогает предотвратить неизбежный отток, но и может помочь вам предвидеть и подготовиться к предпосылкам оттока еще на горизонте.
Давайте возьмем ситуацию, в которой довольно большая группа клиентов ушла в течение определенного периода без видимых объяснений: некоторые были новыми пользователями; некоторые использовали ваш продукт в течение длительного времени. Почему это произошло? Некоторые потенциальные причины могут включать в себя:
- Неудачное изменение продукта
- Экспоненциальный рост в сочетании с высоким оттоком на этапе адаптации
- Запуск нового конкурента, который обслуживает тот же продукт по более низким ценам.
Дело в том, что все эти факторы (некоторые или ни один них) могли вызвать отток — пользователи могли уйти по разным индивидуальным причинам или по одной взаимосвязанной причине. Без подходящего решения для прогнозирования оттока вы не сможете соединить все точки и определить, какие тенденции оттока влияют на ваш бизнес больше всего.
Как это работает
Чтобы предсказать отток, нужно следовать четырем основным шагам.
1. Экспорт и сегментация базы данных клиента
Прогнозирование оттока полностью основано на использовании базы данных вашей компании о вашем клиенте. Вам понадобится анализ ваших клиентов, чтобы точно предсказать, как отток клиентов влияет на ваш бизнес.
Начните с экспорта всех данных, которые могут потенциально могут повлиять на вероятность того, что клиент уйдет. Они могут включать:
- Демографические и поведенческие данные
- Является ли этот пользователь физическим лицом или использует ваш продукт от имени своей компании?
- Какова степень использования сервиса (продукта) в целом и какие функции им доступны?
- Как часто этот пользователь отправляет обращения в службу поддержки?
- Иногда известны данные о гендере и возрасте пользователя, они также могут играть значение.
- Информация о доходах
- Дата подписки — является ли этот пользователь долгосрочным подписчиком или он новый?
- Регулярный месячный доход от этого клиента — индивидуальная ответственность поиска, когда речь заходит о применении вашего прогноза оттока клиентов, вам нужно сначала нацелить клиентов с высокими доходами и риском ухода.
- Состояние подписки
- На каком уровне плана / тарифа находится этот клиент?
- Сколько еще времени в их плане осталось до истечения срока? Это особенно важная часть данных, которую можно использовать, поскольку отток по причине просроченного платежа — это отток, к которому практически любой бизнес SaaS будет наиболее подвержен, и один из самых трудных для предотвращения и отмены.
Как только вы получите необходимые исторические данные, разделите ваших клиентов на сегмент, имеющие отношения к прогнозированию оттока, например:
- Клиенты с многочисленными обновлениями / клиенты ежедневного использования (низкий риск оттока)
- Клиенты, которые поддерживают регулярную связь (заявки в службу поддержки/звонки/запросы на обновление (низкий риск оттока)
- Клиенты, объемы использования сервисом (продуктом) которых, за последний период сократилось (высокий риск оттока)
- Клиенты, которые зарегистрировались, но не завершили регистрацию (высокий риск оттока)
- Клиенты, которые никогда не отправляли заявку в службу поддержки / отправляли много аналогичных заявок в службу поддержки (высокий риск оттока)
2. Продолжить вручную или воспользоваться сервисом прогнозирования.
Как только у вас появились все точки данных, в зависимости от ресурсов, которыми вы располагаете в вашей компании, предсказательная модель, которую вы используете для прогнозирования оттока, может быть либо собственной (пользовательское решение), либо из одной из нескольких доступных сервисов прогнозирования.
Как мы уже отмечали выше, пользовательские решения могут быть адаптированы к количеству и типу данных, которые вы хотите проанализировать, а также к предпочтительному выбору ваших Data Science специалистов, когда речь идет о прогнозировании. Если вам необходимо определить сложные взаимосвязи в ваших данных, то решения на основе машинного обучения вам подойдут. Если вы ищите ответы на другие вопросы, такие как прогнозирование оттока в определенный период времени, нужно использовать анализ выживаемости или риска.
Для компаний, которые хотят использовать стандартное прогнозирующее решение, существует ряд различных доступных вариантов, включая наше решение Celado UnChurn, специально разработанное для анализа, прогнозирования и предотвращения оттока.
3. Используйте свои базы данных, чтобы увидеть, какие клиенты уходят
После того, как вы сегментировали и проанализировали свои данные, вы можете увидеть, какие клиенты подвержены риску оттока. Вы можете найти следующие корреляции:
- Большое количество клиентов уходят после регистрации, в связи с плохо установленными уровнями цен, что приводит к тому, что клиенты выбирают неправильный план для своих нужд
- Низкий уровень общения с постоянными клиентами, что ведет к увеличению числа просроченных платежей по кредитным картам по мере того, как эти ветераны-клиенты уходят от продукта
- Частые всплески оттока после обновлений продукта из-за плохой видимости / инструктивных ресурсов
4. Спасите клиента!
Как только вы убедитесь в правильности управления с теми сегментами клиентов, которые наиболее подвержены оттоку, вы можете начать анализировать, какой аспект их отношений с вашим продуктом приводит к риску оттока. Давайте повторим примеры сверху и посмотрим, как мы могли бы улучшить ситуацию:
- Большое количество клиентов, уходящих после регистрации
- Убедитесь, что ваша страница с ценами предельно ясна относительно того, что предлагается в каждом плане, и какие типы клиентов могут получить наибольшую выгоду от каждого. Оставайтесь с клиентами во время регистрации, чтобы убедиться, что любые неотложные проблемы решены.
- Длительный отток клиентов
- Не принимайте безопасность клиентов-ветеранов как должное. Рассмотрите стимулы, специально предназначенные для них (скидки, специальные предложения по обновлениям, бонусы лояльности), чтобы убедиться, что их глаза не блуждают по вашим конкурентам. Поддерживать стабильный уровень связи, особенно в преддверии истечения срока действия подписки.
- Частые всплески оттока после обновления продукта
- Убедитесь, что обновления продукта видны клиентам заблаговременно и что изменения в функциональности очевидны. Включите ресурсы, чтобы помочь пользователям управлять новыми функциями или усовершенствовать старые.
Еще 3 фактора, влияющих на отток клиентов
Давайте рассмотрим еще несколько потенциальных факторов, способствующих оттоку клиентов.
1. Изменения в обстоятельствах клиента
Клиент может обнаружить, что он получил все необходимое от вашего продукта и больше не нуждается в ваших услугах. С точки зрения качества обслуживания это замечательно: с точки зрения того, что он функционально делает с вашим MRR, не так уж и хорошо. Повторяющийся отток такого типа может означать, что ваш диапазон возможностей ограничен.
Учетная запись может перейти из рук в руки, и новый менеджер учетных записей может захотеть использовать другое программное обеспечение, с которым он более знаком, база данных может просто затеряться во время передачи обслуживания. Этот процесс может быть трудным для переговоров, однако он может быть улучшен за счет целенаправленной коммуникации.
2. Состояние конкуренции
Компания или клиент могут найти сервис (продукт), который нравится им больше, чем ваш, и уйти к конкуренту. Это особенно разрушительная форма оттока, поскольку ваша потеря — это выигрыш вашего конкурента. Этот тип оттока может быть связан с характеристиками и ценами продукта, так и с улучшением обслуживания и клиентского опыта, особенно если конкурент начал снижать ставки.
3. Изменения в характеристиках сервиса (продукта)/его функциональности
Если вы изменив функцию, удалили ее или ввели непопулярное обновление, клиент может посчитать ваш сервис (продукт) менее полезным. Быть восприимчивым к потребностям ваших клиентов очень важно, не только с точки зрения позиционирования вашего сервиса (продукта), но и того, как вы его развития.
Вы можете узнать, что ваши клиенты действительно находят полезным, оценивая данные об их использовании или просто обращаясь к ним напрямую. Если вы проигнорируете эту информацию на свой страх и риск — обновление с полным перечнем изменений функций может привести к неприятной неожиданности.
Профилактика оттока не должна быть сложной
Предсказание оттока может оказаться битвой само по себе, так что вы, вероятно, не хотите слышать, что это, на самом деле, только половина битвы. После того, как вы точно спрогнозировали свой отток, следующий шаг — сделать что-то, что положительно повлияет на тех клиентов, которые могут уйти.
Поддерживать связь
Существует целый ряд причин, по которым клиент может уйти. Одна очень простая, очень распространенная причина: им не помогают извлечь выгоду из вашего сервиса (продукта). В этих случаях общение с клиентом напрямую может стать лучшим способом превратить его из подверженного риску ухода в удовлетворенного.
Отправляйте электронные письма клиентам, которые не получают полной информации о сервисе (продукте) (например, дополнительные возможности) или чьи подписки истекают, оставляя их под угрозой просрочки платежа. Это можно легко сделать с помощью хорошо оптимизированной CRM или хорошей интеграции системы прогноза оттока.
Стимулировать
Акции, скидки, программы лояльности: все они помогают клиентам чувствовать себя ценными и желанными. Вероятно, это поможет убедить их остаться, особенно если ваша рыночная конкуренция сильна, и вы рискуете быть подорванными в финансовом плане или пока работаете над обновлениями функций.
Стимулирование особенно важно для предотвращения того, чтобы клиенты, имеющие неудовлетворённые потребности, могли удовлетворить их немедленно. Стимулы могут выиграть время, пока вы решаете проблемы с производительностью или расширяете свои услуги.
Анализировать отток
Даже лучшая стратегия не является надежной. Клиенты будут по-прежнему уходить (хотя, мы надеемся, в значительно меньшем количестве) независимо от успеха вашего прогноза. Не зарывайте голову в песок; посмотрите на эти цифры и выясните, что пошло не так с этими клиентами.
Отличная стратегия анализа оттока в целом заключается в планировании карты путешествия вашего клиента с вашим сервисом (продуктом). После того как вы определили основные точки, сравните путешествие клиента с вашими данными оттока, и посмотрите, где риск оттока самый высокий. Во время подписки? Через три месяца? Через два года? После обновления?
Вы даже можете обратиться к клиентам, которые ушли для получения отзыва. Они могут не захотеть предоставить его, но любые отзывы такого рода, которые вы можете получить, чрезвычайно ценны.
Полностью интегрированное уменьшение оттока
Если перспектива объединения в единое целое готовых решений по прогнозированию оттока клиентов вызывает у вас головокружение, то интеграция, нацеленная на то, чтобы помочь вам предсказать и сократить отток, является отличным альтернативным вариантом. Как мы уже видели, Celado UnChurn может быть одним из лучших решений такого рода на рынке, изобилующим опытом подписки мирового класса с алгоритмами, которые используют миллионы точек данных, чтобы вернуть клиентов.
Вывод
Компании часто используют пассивный метод, когда речь идет об оттоке — установление максимально низких цен, нацеливание на максимально возможный рост клиентов в месяц — всё, кроме тщательной оценки факторов, влияющих на ваш отток, и обеспечения работы этих данных на себя. Ультра-агрессивные методы продажи могут быть эффективными в краткосрочной перспективе, но вы лечите симптомы, а не болезнь.
Разумный подход к прогнозированию оттока — с помощью интеграции собственного решения — позволит вам понять причины, по которым пользователь может уйти и реагировать на них. Успех пользователя с вашим сервисом (продуктом) может зависеть от самых незначительных условий. Использование прогнозирующего решения для обработки вашего оттока даст вам ясность по каждому из них, и в конечном итоге поможет вам преодолеть отток.
В статье использовались материалы:
BI (бизнес-аналитику) в компании применяют для…
· ликвидации опозданий на работу
· прогнозирования финансового состояния
· распределения премий между сотрудниками
· анализа инновационных товаров
Big Data отражает эффект (феномен)…
· скорости интернет
· разнообразия данных
· криптовалютных отношений
· отказа от баз данных
BigData – это …
· Представление фактов, понятий или инструкций в форме, приемлемой для интерпретации, или обработки
· Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
· Колоссальный объем данных, собранных человечеством
· Класс в Java, предназначенный для хранения данных от 100 Гб
BigData – это…
· Класс в Java, предназначенный для хранения данных от 100 Гб
· Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
· Колоссальный объем данных, собранных человечеством
· Представление фактов, понятий или инструкций в форме, приемлемой для интерпретации, или обработки
Data Mining — это процесс обнаружения в сырых данных знаний, необходимых для…
· Принятия решений в различных сферах человеческой деятельности
· Замены аналитика в процессе принятия решений
· Увеличения стоимости анализа данных
· Уменьшения стоимости анализа данных
Data Mining позволяет всегда…
· увеличивать объем данных
· визуализировать данные
· избавляться от спама
· применять лишь 2D-представление данных
Hadoop – это…
· набор утилит, и программный каркас для выполнения распределённых программ, работающих на кластерах
· распределённая СУБД, позволяющая обрабатывать большие данные
· язык выполнения заданий в парадигме MapReduce
· распределённая файловая система, предназначенная для хранения файлов большого объёма
R не является…
· языком программирования для статистической обработки данных и работы с графикой, созданный на основе языка S
· свободной программной средой вычислений с открытым исходным кодом
· высокоуровневым языком программирования общего назначения, ориентированным на повышение производительности разработчика и читаемости кода
· языком программирования с динамической типизацией данных
Аналитик это …
· специалист в области анализа и моделирования
· специалист в предметной области
· человек, решающий определенные задачи
· человек, который имеет опыт в программировании
Более полно и точно, краудсорсинг – это модель…
· передачи управления народу
· типа договора оферта
· договора подряда
· оплаты по максимальной ставке
В 2016 году программа AlphaGo обыграла одного из мировых по шахматам чемпионов Ли Седоля. Какая компания разработала ИИ AlphaGo?
· Microsoft
· Yandex
В Big Data возможны…
· виртуальные типы данных
· лишь одинакового типа данные
· лишь одинакового типа данные
· лишь одинаковые области применения данных
· разные типы и области происхождения данных
В Big Data не акцентируется…
· Volume (Объем)
· Velocity (Скорость)
· Variety (Разнообразие)
· Voicing (Озвучивание)
В базе данных есть следующие записи: длительность звонков, общее число звонков, общее число переданных сообщений, количество потраченных гигабайтов трафика. Вы хотите предсказывать объем трафика, который потратят клиенты. Что будет объектом модели в этой задаче?
· Длительность звонков
· Общее число звонков
· Клиент
· Количество трафика
В какие игры нейросеть еще не научилась обыгрывать человека?
· Го
· «Марио»
· Бридж
· Шахматы
В каком году впервые был введен термин Большие данные?
· 2002
· 2004
· 2006
· 2008
В каком из приведённых примеров наиболее эффективны NoSQL решения типа ключ-значение?
· потоковая обработка логов кластера серверов и быстрого сохранения без требования оперативной аналитики
· оперативная аналитика сохранённых логов кластера серверов
· кластеризация логов кластера серверов на основе заранее известных признаков лог-файла
· хранение данных о клиентах международной корпорации
В краудсорсинге вклад в проект каждого участника осуществляется…
· лишь финансами
· лишь затратами времени
· ресурсами – компьютер, время и др.
· привлечением аутсорсинга
В краудсорсинге могут быть задействованы…
· лишь профессионалы
· лишь любители
· разработчики площадки и посетители
· профессионалы и любители
В любых Big Data информация целиком распределена…
· по компьютеру
· по всей сети
· по всему интернет
· по всем облакам
В результате использования инструментов Data Mining пользователь может …
· Получить гипотезы о взаимосвязях в данных, самостоятельно выдвинутые инструментом Data Mining
· Получить подтверждение или опровержение гипотез, выдвинутых пользователем
· Проверить гипотезы о взаимосвязях в данных, самостоятельно выдвинутые пользователем инструмента Data Mining
В чём преимущество колоночно-ориентированных СУБД?
· они позволяют выполнять более сложные SQL-запросы по сравнению с реляционными СУБД
· они позволяют динамически дополнять содержание записей новыми полями
· они имеют более гибкие возможности аналитики
· они позволяют эффективно делать межколоночные сравнения
Вы взяли среднесуточные температуры за последние два года и построили регрессионную модель для прогнозирования дневного спроса на товары. Для мороженого она работает хорошо, а для шуб плохо. Почему?
· Шубы продают нечасто — мало данных
· На рынке шуб много «серых» продаж — данные недостоверны
· Продажи шуб вообще нельзя спрогнозировать
· Мороженое — спонтанная покупка
Выберите верное высказывание…
· большие данные – это обработка или хранение более 1 Тб информации
· проблема больших данных – это такая проблема, когда при существующих технологиях хранения и обработки сущностная обработка данных затруднена или невозможна
· большие данные – это огромная PR-акция крупных вендоров и не более того
· большие данные – это явление, когда цифровые данные наиболее полно представляют изучаемый объект
Выберите неверное высказывание про MapReduce…
· интерфейс для массово-параллельной обработки данных, где вычисления производятся на узлах, где информация изначально была сохранена
· MapReduce – это две операции: распределения и сборки данных
· MapReduce был придуман разработчиками Hadoop
· MapReduce был анонсирован разработчиками Google
Выберите неверное высказывание…
· большие данные – это данные объёма свыше 1 Тб
· проблема больших данных – это проблема, когда при существующих технологиях хранения и обработки сущностная обработка данных затруднена или невозможна
· большие данные – это тренд в области ИТ, подогреваемый маркетинговыми кампаниями крупных вендоров
· большие данные как правило не структурированы
Выберите технологию потоковой обработки событий в режиме реального времени
· Apache Kafka
· Apache Hadoop
· MapReduce
· Spark Streaming
Горизонтальная масштабируемость при обработке Big Data – это…
· расширение механизма обработки данных при росте объема данных
· увеличение скорости обработки при росте объема данных
· спад скорости обработки при росте объема данных
· изменение масштабов представления результатов обработки данных
Дайте определение Big Data
· Комплексный набор инструментов обработки структурированных данных колоссальных объемов
· Комплексный набор подходов, инструментов и методов обработки структурированных и неструктурированных данных колоссальных объемов
· Комплексный набор методов обработки неструктурированных данных колоссаль
· Комплексный набор методов обработки структурированных данных колоссальных объемов
Дайте определение Map Reduce…
· Модель распределенных вычислений, предназначенная для параллельных вычислений над очень большими (до нескольких петабайт) объемами данных
· Набор компонентов и интерфейсов для распределенных файловых систем и общего ввода-вывода
· Распределенная файловая система, работающая на больших кластерах типовых машин
· Распределенный сервис для коллекционирования, сбора, и перемещения больших массивов данных
Данные могут быть получены в результате…
· Измерений
· Экспериментов
· Арифметических и логических операций
Данные представляют собой…
· Факты и графики
· Текст
· Картинки, звуки, аналоговые или цифровые видео-сегменты
Для машинного обучения подходят данные…
· Бинарные
· Числовые типа int
· Любых форматов в цифровом виде
· Предварительно подготовленные, очищенные от ошибок, пропусков и выбросов, а также нормализованные и представленные в виде числовых векторов
Для обработки больших данных наиболее актуально…
· привлечь больше вычислительных мощностей для обработки
· ускорить обработку или увеличить объем обрабатываемых данных
· заработать обработкой данных или обрабатывать их для заработка
· оставить для обработки только однотипные данные (например, числовые)
До появления Big Data невозможно было…
· обрабатывать всю вузовскую информацию полностью
· управлять автоматизированной линией по сборке авто
· оплачивать товары в электронных платежных системах
· работать с данными дистанционного зондирования Земли
До появления Data Mining невозможно было найти связи…
· студентов вуза и их успеваемости по предмету
· течения COVID-19 и осложнений после заболевания по всей РФ
· рекламирования и покупательской активности на сайте веб-магазина
· сроков доставки заказа через службу доставки и числом курьеров
Допустим, нам нужно рассчитать необходимые параметры для создания обшивки самолета. Какая из областей машинного обучения нам в этом пригодится?
· Латентная модель
· Обучение ранжированию
· Компьютерное зрение
· Предсказательное моделирование
Закончите следующее предложение: «С точки зрения машины, информация становится структурированной, если…
· Машина проинструктирована, каким образом её обрабатывать
· Информация разделена на части и озаглавлена
· Информация имеет логическую взаимосвязь внутри себя
· Машина знает из каких частей состоит информация
Изначально Big Data применяли лишь в…
· геологии
· академической среде
· спутниковой связи
· криптовалютах
Интеллектуальный анализ данных или Data Mining…
· Информация, которая организована и проанализирована с целью сделать ее понятной и применимой для решения задачи или принятия решений.
· Оперативная обработка транзакций
· Термин, используемый для описания открытия знаний в базах данных, выделения знаний, изыскания данных, исследования данных, обработки образцов данных, очистки и сбора данных; здесь же подразумевается сопутствующее ПО
· Оперативная обработка транзакций
Искусственные нейронные сети (ИНС) — модели машинного обучения, использующие комбинации распределенных простых операций, зависящих от обучаемых параметров, для обработки входных данных. Какого вида ИНС не существует?
· Наивные
· Рекуррентные
· Импульсные
· Противоборствующие
Искусственный интеллект научился разбираться в музыке. Насколько хорошо работает программа по определению музыкальных стилей? Сможет ли такая программа справиться с заданием типа «Угадай мелодию» в режиме реального времени?
· да, лучше, чем программа, написанная вручную
· да, но программа написанная вручную будет точнее
· нет, в режиме реального времени программа не справится
· справится, но не в режиме реального времени
Итак, вы решили работать с большими данными. Какой из этих инструментов вам вряд ли пригодится?
· SQL
· Texmaker
· Python
· R
Как происходит обучение нейронной сети?
· эксперты настраивают нейронную сеть
· сеть запускается на обучающем множестве, и незадействованные нейроны выкидываются
· сеть запускается на обучающем множестве, и подстраиваются весовые значения
· сеть запускается на обучающем множестве, и добавляются или убираются соединения между нейронами
Какая информация о пациентах, находящаяся в распоряжении медицинской организации, относится к персональным данным?
· Диагнозы конкретных пациентов
· Количество пациентов медицинской организации
· Данные из электронной медицинской карты без Ф.И.О.: дата рождения, адрес регистрации и пр.
· Динамика роста случаев конкретного заболевания
Какая компания создала технологию MapReduce?
· Yahoo
· EMC
· Oracle
Какие задачи решают графовые БД?
· хранение информации о других БД
· хранение информации о других БД
· распределенное хранение с учетом минимизации передачи информации
· использование графа серверов для распределенного хранения больших данных
· встроенная обработка данных сетевыми методами
Какие из задач решаются Big Data?
· Мониторинг оборудования
· Анализ социальных сетей
· Оптимизация автомобильного движения
· Все вышеперечисленное
Какие из следующих технологий СУБД не используют принцип MapReduce?
· Hadoop
· Cassandra
· HDInsight
· Redis
Какие модули по умолчанию yt входят в состав проекта Apache Hadoop?
· HDFS
· Spark
· MapReduce
· YARN
Какое API было добавлено в Hadoop v2.0?
· YAWN
· YARN
· SARN
· DARN
Какое из нижеперечисленных понятий не относится к перечню необходимых критериев для создания проекта, связанного с Большими данными?
· Географическое положение
· Производительность
· Гибкость анализа
· Скорость принятия решения
Какой тип NoSQL решения наиболее эффективен для потоковой обработки логов кластера серверов и быстрого сохранения без требования оперативной аналитики?
· документоориентированные
· колоночно-ориентированные
· колоночно-ориентированные
· ключ-значение
· графовая
Какой язык программирования из перечисленных является наиболее важным для аналитика?
· C++
· PHP
· F#
· R
Краудсорсинг – модель привлечения…
· ограниченного числа участников и их потенциала
· лишь большого бизнеса
· лишь малого бизнеса
· неограниченного числа и потенциала участников
Краудсорсинг большого проекта невозможен без…
· соединения его с другими проектами, композиции
· выделения его частей, декомпозиции
· экспертной оценки
· финансирования крупным банком
Кто ввел термин Большие данные?
· Клиффорд Линч
· Алан Тьюринг
· Бьерн Страуструп
· Дональд Кнут
Кто и в каком году впервые ввел термин «Big Data»?
· Разработчик компании Google в 2009 году
· Инженер компании Amazon в 2006 году
· Клиффорд Линч, редактор журнала Nature, в 2008 году
· Профессор Стэнфордского университета в 2007 году
Локальность данных Big Data – это…
· расширение механизма обработки данных при росте объема данных
· информация на одном компьютере сети обрабатывается на другом
· время коммуникации не может быть выше времени обработки
· данные не стоит обрабатывать на сервере их хранения
На каком языке программирования можно разрабатывать приложения Hadoop MapReduce?
· Практически на любом: Java, C++ и другие компилируемые языки
· C#
· Только Java
· Python
На основе какого языка был создан R?
· C
· S
· Java
· Python
Недостатком краудсорсинга является…
· неограниченная эффективность
· большие затраты
· ограниченная мотивация
· простота управления
Нейросети хорошо проявляют себя не только в распознавании, но и в генерации изображений. Но кое с чем у них все-таки возникают проблемы. С чем именно?
· Форма
· Текстуры
· Глубина, количество пикселей
· Цвет
Обрабатывать большие данные (Big Data) лет десять назад мешали…
· слабые токи в интернет-сетях
· базы данных табличного типа
· неграмотные в области ИКТ пользователи
· недостаточные вычислительные мощности
Одна из главных целей Big Data – это…
· привлечение все больше пользователей
· рост числа обработок данных
· нижение издержек операций
· таргетирование пользователей
Одна из главных целей Data Mining – это получение…
· связей малых выборок данных, распространение их на большие массивы
· скриншотов всех обработок данных
· аудита сайтов, веб-ресурсов
· гарантированной сетевой безопасности
Основными достоинствами краудсорсинга не являются…
· масштабируемость
· отсутствие рисков
· бесплатная рабочая сила
· символическая оплата
Основными достоинствами краудсорсинга являются…
· масштабируемость и отсутствие рисков
· оперативность реализации проекта и распределения прибыли
· необязательность веб-поддержки
· разделение рисков по исполнителям
Особых успехов нейросети достигли в работе с изображениями. Но что из этого нейросети не могут сделать?
· Стилизовать вашу фотографию под работу импрессиониста
· Догадаться, что вы нарисовали
· Омолаживать и состаривать лица на фотографиях
· Пластическую коррекцию лица
Отказоустойчивость Big Data – это, когда…
· активируются до 1000 компьютеров
· сбой в одном звене системы не ведет к сбоям в других звеньях
· недостоверные данные удаляются из системы
· данные обрабатываются на других серверах
Отметьте верное понимание Variety в контексте характеристик Big Data…
· высокая скорость генерирования данных
· разные типы данных в колонках таблиц реляционных СУБД
· разнообразие отраслей, являющихся источниками данных
· разнообразие типов данных, включающих в себя структурированные, полуструктурированные и неструктурированные
Отметьте причину создания NoSQL баз данных…
· высокая стоимость горизонтальной масштабируемости RDBMS при сохранении требования высокой доступности
· недостаточная гибкость языка запросов SQL
· невозможность хранить большие объёмы данных
· дороговизна лицензий RDBMS
Отметьте те из вариантов, в которых данные структурированы…
· данные о продажах компании, представленные в виде помесячных отчётов в формате MS Word
· таблица с ежедневными показаниями температуры помещения за год в файле формата csv
· текст педагогической поэмы А.С. Макаренко, представленный в формате PDF
· библиотека фильмов, представленных в формате mpeg4 на одном жестком диске
Перечислите четыре основных характеристики Big Data…
· Virtualization, Volume, Variability, Vehicle
· Variety, Velocity, Volume, Value
· Verification, Volume, Velocity, Visualization
· Video, Value, Variety, Volume
Подходы к построению моделей Data Mining
· статистический и на основании машинного обучения
· на основании машинного обучения и вычислительный
· вычислительный и статистический
Пример благоразумного использования Hadoop…
· анализ 10 Гб данных
· ежедневное сохранение данных температуры, поступающих со всех городов России (по одному показанию на город, всего городов 1100 шт)
· посекундное сохранение данных температуры, поступающих со всех городов России (по одному показанию на город, всего городов 1100 шт)
· построение графика пульса пациента в реальном времени
Примером применения Big Data не может быть…
· зондирование Земли из космоса
· родительский контроль
· хранение данных клиентов в соцсетях
· доступ к крупнейшим библиотекам
Принцип 3Vs расшифровывается как…
· Value, Variety, Velocity
· Volume, Veracity, Velocity
· Volume, Variety, Velocity
· Value, Veracity, Velocity
Принципом Big Data не является…
· горизонтальная масштабируемость
· локализация данных
· отказоустойчивость обработки
· мобильность приложений
Программа от Google научилась рисовать на основе эскизов, сделанных людьми. Что при этом учитывала программа?
· стиль типичный для похожих изображений
· только конечный результат
· концепцию (идею) рисунка
· цветовую гамму типичную для похожих изображений
Расписание движения поездов может рассматриваться как пример…
· Табличной модели
· Натурной модели
· Математической модели
· Графической модели
Распределенная архитектура Big Data позволяет всегда…
· защищать каждому пользователю данные страницы другого пользователя
· распределять по соцсети фото, сообщения
· распределять справедливо доход от рекламы в сетях
· распределять зарплату таргетологов
С помощью Big Data клиентский компьютер может обрабатывать до…
· терабайтов данных
· мегабайтов данных
· гугол данных
· петабайтов данных
Сколько Петабайт в Зеттабайте?
· 1024
· 128
· 32
· 4
Специалист по работе с данными знает и умеет многое, но нельзя знать всего. Чего не преподают на курсах по Data Science?
· Выявление аномалий
· Кластерный анализ
· Масс-спектрометрия
· Регрессионный анализ
Теперь вам нужно обучить нейросеть распознавать на фото воздушные шары. Коллега предлагает перевести все изображения для обучения нейросети в черно-белые. Что вы ответите?
· Нет, потому что это невозможно
· Нет, потому что это ухудшит результат
· Да, потому что значение имеет только форма
· Да, потому что цвета можно добавить потом
Традиционные методы визуализации могут находить следующее применение…
· Представлять пользователю информацию в наглядном виде
· Компактно описывать закономерности, присущие исходному набору данных
· Снижение размерности или сжатие информации
У машинного обучения есть ряд задач. Как называется та, что направлена на предсказание значения той или иной непрерывной числовой величины для входных данных?
· Кластеризация
· Классификация
· Переобучение
· Регрессия
Укажите фактор, способствовавший появлению тренда больших данных…
· маркетинговые кампании крупных корпораций
· повышение издержек на хранение данных
· появление новых технологий обработки потоковых данных
· выпуск баз данных с обработкой данных в памяти
Чего не могут стандартные реляционные базы (MySQL, Oracle, MS SQL)?
· хранить данные с изменяющейся структурой
· хранить данные на нескольких физических серверах
· хранить большие объемы (терабайты+)
· обрабатывать запросы большого количества клиентов (миллионы)
Чем глубокое обучение отличается от машинного?
· Машинное обучение — это обучение нейронной сети без применения невычислимых алгоритмов, а глубокое обучение — это обучение сети с использованием таких алгоритмов
· Машинное обучение изучает алгоритмы, обучающиеся без использования специального свода правил, а глубокое обучение — это машинное обучение нейронных сетей с более чем тремя скрытыми слоями нейронов
· Машинное обучение и глубокое обучение по сути одно и то же
· Машинное обучение — это обучение компьютерных алгоритмов без специального свода правил, а глубокое обучение использует все возможные известные виды обучения
Чем искусственная нейронная сеть похожа на естественные нейронные сети в мозге?
· Искусственная нейронная полностью повторяет строение и функции сетей в мозге
· В искусственной нейронной сети повторяется микроструктура связей сетей в мозге
· Их объединяет лишь общий принцип построения: это последовательность связанных друг с другом нейронов
· Так сложилось исторически: эти сети ничего не объединяет, кроме общего слова в названии
Что будет объектом в задаче поиска уходящих от компании клиентов?
· Уход клиента
· Количество дней, через которые клиент уйдет
· Клиент
· Услуга, от которой отказывается клиент
Что из перечисленного помогает следить за эволюцией документа, над созданием которого работает одновременно большое количество авторов?
· Пространственный поток
· Исторический поток
· Визуальный поток
· Интерактивный поток
Что из этого не является типом визуализации?
· График
· Текст
· Круговая диаграмма
· Гистограмма
Что не является целью процесса Business Intelligence?
· Интерпретация большого количества данных
· Моделирование исходов различных вариантов действий
· Модификация существующего программного обеспечения
· Отслеживание результатов решений
Что необходимо выполнить, чтобы нейросеть могла помочь в формировании решения…
· Указать правила вывода
· Указать формулы для расчетов
· Обучить на примерах
· Ввести информацию о ситуации
Что означает термин «Big Data» в информационных технологиях?
· Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
· Представление времени, дня, месяца и года в качестве значения количества миллисекунд, прошедших с начала нашей эры
· Файлы с большим количеством данных
· Комплексный набор методов для создания файлов большого объёма
Что означает термин «Business Intelligence» в информационных технологиях?
· Комплексный набор методов для создания бизнес планов.
· Методы и инструменты для перевода необработанной информации в осмысленную, удобную для восприятия форму
· Файлы, содержащие информацию о бизнес плане
· Технологии, направленные на развитие бизнеса
Что означает термин NoSQL?
· Не SQL
· Не только SQL
· Без SQL
· SQL – плохо
Что такое EDA?
· Исследовательский анализ данных
· Прогностическая аналитика данных
· Эпизодический анализ данных
· Интеллектуальный кластер
Что такое Spark?
· Инструмент для кластерных вычислений
· Графический движок
· Библиотека для работы с графами
· Технология распределенных вычислений
Что такое SQL?
· Реляционная база данных
· Язык неструктурированных запросов
· Язык структурированных запросов
· Средство для создания пайплайнов
Что такое БУСТИНГ?
· Резкое увеличение объёма поступающих данных
· Метод анализа эффективности прогноза
· Встроенная кросс-валидация данных
· Построение ансамбля моделей машинного обучения
Чтобы работать с большими данными, их сначала нужно собрать. А с этого года действует GDPR — общеевропейский регламент о защите персональных данных. В каких случаях по регламенту не требуется согласие человека на обработку его данных?
· Таких случаев не предусмотрено
· Если данные остаются внутри компании
· Когда данные используются для защиты общественной безопасности
· При условии, что данные «видят» только алгоритмы, но не люди
Эффективно применять Data Mining с целью защиты от…
· мошенников
· инфицирующих ботов
· инфицированных клиентов
· инсайдеров
Моделирование оттока (Churn Modeling, Churn Prediction) – одна из популярнейших задач Машинного обучения (ML), нацеленная на удержание пользователей с определенными поведением и характеристиками. Рассмотрим в качестве примера кейс американского провайдера услуг связи Telco. Мы будем использовать JavaScript.
«Предсказывайте поведение, чтобы удерживать клиентов. Вы можете анализировать все соответствующие данные о клиентах и разрабатывать целенаправленные программы их удержания».
Датасет (Dataset) имеет 7044 записи и 21 столбец:
- customerID: идентификатор клиента
- Gender: является ли клиент мужчиной или женщиной
- SeniorCitizen: является ли клиент пожилым гражданином (да, нет)
- Partner: есть ли у клиента партнер (да, нет)
- Dependents: есть ли у клиента иждивенцы (да, нет)
- Tenure: количество месяцев, в течение которых клиент оставался в компании
- PhoneService: есть ли у клиента телефония (да, нет)
- MultipleLines: есть ли у клиента несколько линий (да, нет, нет телефонии)
- InternetService: интернет-провайдер клиента (DSL, оптоволокно, нет)
- OnlineSecurity: есть ли у клиента онлайн-безопасность (да, нет, нет интернет-сервиса)
- OnlineBackup: есть ли у клиента онлайн-резервное копирование (да, нет, нет интернет-сервиса)
- DeviceProtection: есть ли у клиента защита устройства (да, нет, нет интернет-сервиса)
- TechSupport: есть ли у клиента техническая поддержка (да, нет, нет интернет-сервиса)
- StreamingTV: есть ли у клиента потоковое телевидение (да, нет, нет интернет-сервиса)
- StreamingMovies: есть ли у клиента потоковые фильмы (да, нет, нет интернет-сервиса)
- Contract: срок контракта клиента (ежемесячно, один год, два года)
- PaperlessBilling: есть ли у клиента безбумажный биллинг (да, нет)
- PaymentMethod: способ оплаты клиента (электронный чек, чек по почте, автоматический банковский перевод, автоплатеж с карты)
- MonthlyCharges: сумма, взимаемая с клиента ежемесячно
- TotalCharges: общая сумма, списанная с клиента
- Churn: ушел ли клиент или нет (да или нет)
Мы будем использовать Papa Parse для загрузки данных:
const prepareData = async () => {
const csv = await Papa.parsePromise(
«https://raw.githubusercontent.com/curiousily/Customer-Churn-Detection-with-TensorFlow-js/master/src/data/customer-churn.csv»
);
const data = csv.data;
return data.slice(0, data.length — 1);
};
Обратите внимание, что мы игнорируем последнюю строку, так как она пуста.
Разведочный анализ данных
Давайте поизучаем наш набор данных. Сколько клиентов ушло?

Около 74% клиентов продолжают пользоваться услугами компании. У нас очень несбалансированный набор данных.
Влияет ли пол на вероятность ухода?

Кажется, нет. У нас примерно одинаковое количество клиентов женского и мужского пола. Как насчет возраста?

Около 20% клиентов – пожилые, и они гораздо чаще уходят.
Как долго клиенты остаются в компании?

Кажется, что чем дольше вы остаетесь, тем больше вероятность, что вы останетесь с Telco и дальше.
Как ежемесячные платежи влияют на отток?

Покупатель с низкими ежемесячными платежами (<30 долларов США) с гораздо большей вероятностью будет удержан.
Как насчет общей суммы, взимаемой с клиента?

Чем выше общая списанная сумма средств, тем больше вероятность того, что этот клиент останется.
В нашем наборе данных всего 21 Признак (Feature), и мы не просматривали их все. Тем не менее, мы нашли кое-что интересное.
Мы узнали, что столбцы SeniorCitizen, tenure, MonthlyCharges и TotalCharges в некоторой степени коррелируют со статусом оттока. Мы будем использовать их для нашей модели.
Глубокое обучение
Глубокое обучение (Deep Learning) — это подраздел Машинного обучения, связанный с алгоритмами, основанными на структуре и функциях мозга – искусственными Нейронными сетями (Neural Network).
Чтобы получить глубокую нейронную сеть, возьмите нейронную сеть с одним скрытым слоем (мелкая нейронная сеть) и добавьте больше слоев: это определение глубокой нейронной сети.
В глубоких нейронных сетях каждый слой обучается на выходных данных предыдущего слоя. Таким образом, мы можем создать иерархию функций-столбцов с возрастающей абстракцией и изучать сложные концепции.
Эти сети очень хорошо обнаруживают закономерности в необработанных данных (изображениях, текстах, видео- и аудиозаписях), а это самый большой объем данных, который у нас есть. Например, Deep Learning может взять миллионы изображений и разделить их на фотографии вашей бабушки, забавных кошек и вкусных тортов.
Глубокие нейронные сети – передовой метод решения целого ряда проблем, таких как распознавание изображений, их сегментация, распознавание звука, рекомендательные системы, обработка естественного языка и т. д.
Таким образом, глубокое обучение — это большие нейронные сети. Почему сейчас? Почему глубокое обучение не было практичным раньше?
- Для большинства реальных приложений глубокого обучения требуются большие объемы размеченных данных: для разработки беспилотного автомобиля могут потребоваться тысячи часов видео.
- Обучающие модели с большим количеством параметров требуют значительных вычислительных мощностей: аппаратное обеспечение специального назначения в форма GPU и TPU предлагает массовые параллельные вычисления.
- Крупные компании уже некоторое время хранят ваши данные: они хотят их монетизировать.
- Мы узнали (вроде как), как инициализировать Веса (Weights) нейронов в моделях нейронной сети: в основном, используя небольшие случайные значения.
- У нас есть лучшие методы Регуляризации (Regularization)
И последнее, но не менее важное: у нас есть программное обеспечение, которое является производительным и простым в использовании. Такие библиотеки, как TensorFlow, PyTorch, MXNet и Chainer, позволяют специалистам-практикам разрабатывать, анализировать, тестировать и развертывать модели различной сложности, а также повторно использовать результаты работы других специалистов-практиков и исследователей.
Прогнозирование оттока клиентов
Давайте воспользуемся механизмом глубокого обучения, чтобы предсказать, какие клиенты собираются уйти. Во-первых, нам нужно выполнить некоторую предварительную обработку данных, поскольку многие столбцы являются категориальными.
Предварительная обработка данных
Мы будем использовать все числовые (кроме customerID) и следующие категориальные признаки:
const categoricalFeatures = new Set([
«TechSupport»,
«Contract»,
«PaymentMethod»,
«gender»,
«Partner»,
«InternetService»,
«Dependents»,
«PhoneService»,
«TechSupport»,
«StreamingTV»,
«PaperlessBilling»
]);
Давайте создадим наборы данных для обучения и тестирования из наших данных:
const [xTrain, xTest, yTrain, yTest] = toTensors(
data,
categoricalFeatures,
0.1
);
Вот как мы создаем наши Тензоры (Tensor) — многомерные массивы чисел:
const toTensors = (data, categoricalFeatures, testSize) => {
const categoricalData = {};
categoricalFeatures.forEach(f => {
categoricalData[f] = toCategorical(data, f);
});
const features = [
«SeniorCitizen»,
«tenure»,
«MonthlyCharges»,
«TotalCharges»
].concat(Array.from(categoricalFeatures));
const X = data.map((r, i) =>
features.flatMap(f => {
if (categoricalFeatures.has(f)) {
return categoricalData[f][i];
}
return r[f];
})
);
const X_t = normalize(tf.tensor2d(X));
const y = tf.tensor(toCategorical(data, «Churn»));
const splitIdx = parseInt((1 — testSize) * data.length, 10);
const [xTrain, xTest] = tf.split(X_t, [splitIdx, data.length — splitIdx]);
const [yTrain, yTest] = tf.split(y, [splitIdx, data.length — splitIdx]);
return [xTrain, xTest, yTrain, yTest];
};
Во-первых, мы используем функцию toCategorical() для преобразования категориальных признаков в векторы с использованием Быстрого кодирования (One-Hot Encoding). Мы делаем это, конвертируя строковые значения в числа и используя tf.oneHot() для создания векторов.
Мы создаем двумерный тензор из наших признаков (категориальных и числовых) и нормализуем его. Другой тензор с горячим кодированием сделан из столбца Churn.
Наконец, мы разделяем набор на Тренировочные данные (Train Data) и Тестовые (Test Data) и возвращаем результаты. Как мы кодируем категориальные переменные?
const toCategorical = (data, column) => {
const values = data.map(r => r[column]);
const uniqueValues = new Set(values);
const mapping = {};
Array.from(uniqueValues).forEach((i, v) => {
mapping[i] = v;
});
const encoded = values
.map(v => {
if (!v) {
return 0;
}
return mapping[v];
})
.map(v => oneHot(v, uniqueValues.size));
return encoded;
};
Сначала мы извлекаем вектор всех значений признака. Затем мы получаем уникальные значения и превращаем строковые значения в целочисленные.
Обратите внимание, что мы проверяем пропущенные значения и кодируем их как 0. Наконец, мы кодируем каждое значение.
Вот остальные служебные функции:
// нормализованное_значение = (значение − минимум) / (максимум − минимум)
const normalize = tensor =>
tf.div(
tf.sub(tensor, tf.min(tensor)),
tf.sub(tf.max(tensor), tf.min(tensor))
);
const oneHot = (val, categoryCount) =>
Array.from(tf.oneHot(val, categoryCount).dataSync());
Создание глубокой нейронной сети
Мы завершим построение и обучение нашей модели в функцию с именем trainModel():
const trainModel = async (xTrain, yTrain) => {
// Сейчас подробно рассмотрим, что внутри
…
return model;
};
Давайте создадим глубокую нейронную сеть, используя API последовательной модели в TensorFlow:
const model = tf.sequential();
model.add(
tf.layers.dense({
units: 32,
activation: «relu»,
inputShape: [xTrain.shape[1]]
})
);
model.add(
tf.layers.dense({
units: 64,
activation: «relu»
})
);
model.add(tf.layers.dense({ units: 2, activation: «softmax» }));
Наша глубокая нейронная сеть имеет два скрытых слоя с 32 и 64 нейронами соответственно. Каждый слой имеет Функция активации выпрямителя (ReLU).
Время скомпилировать нашу модель:
model.compile({
optimizer: tf.train.adam(0.001),
loss: «binaryCrossentropy»,
metrics: [«accuracy»]
});
Мы будем обучать нашу модель с помощью оптимизатора «Адаптивная оценка момента» (Adam) и измерять нашу ошибку с помощью бинарной Кросс- энтропии (Cross-Entropy).
Обучение
Наконец, мы передадим обучающие данные нашей модели и обучимся на них в течение 100 эпох, перемешаем данные и используем 10% для проверки. Визуализируем ход обучения с помощью tfjs-vis:
const lossContainer = document.getElementById(«loss-cont»);
await model.fit(xTrain, yTrain, {
batchSize: 32,
epochs: 100,
shuffle: true,
validationSplit: 0.1,
callbacks: tfvis.show.fitCallbacks(
lossContainer,
[«loss», «val_loss», «acc», «val_acc»],
{
callbacks: [«onEpochEnd»]
}
)
});
Давайте обучим нашу модель:
const model = await trainModel(xTrain, yTrain);


Похоже, что наша модель обучается в течение первых десяти эпох и выходит на плато после этого.
Оценка модели
Оценим нашу модель на тестовых данных:
const result = model.evaluate(xTest, yTest, {
batchSize: 32
});
// Потери
result[0].print();
// Точность
result[1].print();
Модель имеет точность 79,2% на тестовых данных:
Tensor 0.44808024168014526
Tensor 0.7929078340530396
Давайте посмотрим, какие ошибки он допускает, используя Матрицу ошибок (Confusion Matrix):
const preds = model.predict(xTest).argMax(-1);
const labels = yTest.argMax(-1);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = document.getElementById(«confusion-matrix»);
tfvis.render.confusionMatrix(container, {
values: confusionMatrix,
tickLabels: [«Retained», «Churned»]
});

Похоже, что наша модель слишком самоуверенна в прогнозировании удержания клиентов. В зависимости от потребностей мы можем перенастроить модель и улучшить ее предсказательную способность.
Песочница, не требующая дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Venelin Valkov
20 февраля 2023
Отток клиентов: как контролировать уход пользователей
Отток для компании — это потеря клиентов. В небольшом количестве он незаметен, потому что приходят новые клиенты. Если же отток приобретает массовый характер, выручка падает.
В статье рассмотрим причины оттока и способы борьбы с ним в B2B- и B2C-сегментах. Как примеры приводим кейсы компаний FOAM, «585*ЗОЛОТОЙ», Flor2U, Sunlight и Mindbox.
Отток клиентов: как контролировать уход пользователей
Отток для компании — это потеря клиентов. В небольшом количестве он незаметен, потому что приходят новые клиенты. Если же отток приобретает массовый характер, выручка падает.
В статье рассмотрим причины оттока и способы борьбы с ним в B2B- и B2C-сегментах. Как примеры приводим кейсы компаний FOAM, «585*ЗОЛОТОЙ», Flor2U, Sunlight и Mindbox.
Почему клиенты уходят
Отток клиентов может быть естественным и мотивационным. На естественный отток компания не может повлиять, потому что он зависит от жизненных обстоятельств клиента. Это переезд, взросление ребенка или изменение потребностей. Если клиент переехал в другую страну, то покупать товары в российских магазинах он перестанет.
Мотивационный отток чаще всего вызван действиями самой компании: увеличением цен, ухудшением качества товаров или уровня сервиса. Такой отток компания может сократить. Например, клиенту, который нашел более дешевый товар у конкурентов, можно дать скидку.
Основные причины мотивационного оттока:
- недовольство качеством продукта;
- резкое повышение цен на товары;
- более выгодные предложения конкурентов;
- несвоевременная доставка;
- сложный процесс покупки товара на сайте;
- недоступность службы поддержки;
- клиенты забыли о бренде и заказали в другом месте;
- появление у конкурентов аналогов лучшего качества.
Мнение
Отток — это расставание клиентов с компанией, похожее на расставание людей, бизнес-партнеров, сотрудников. Расстаются всегда по какой-то причине, которую важно понять и решить в будущем.
Как точно выяснить причины оттока клиентов
1. Собрать обратную связь от клиентов
Обратная связь поможет компании улучшить товары и процессы. Собирать ее можно по телефону, по email и на своем сайте.
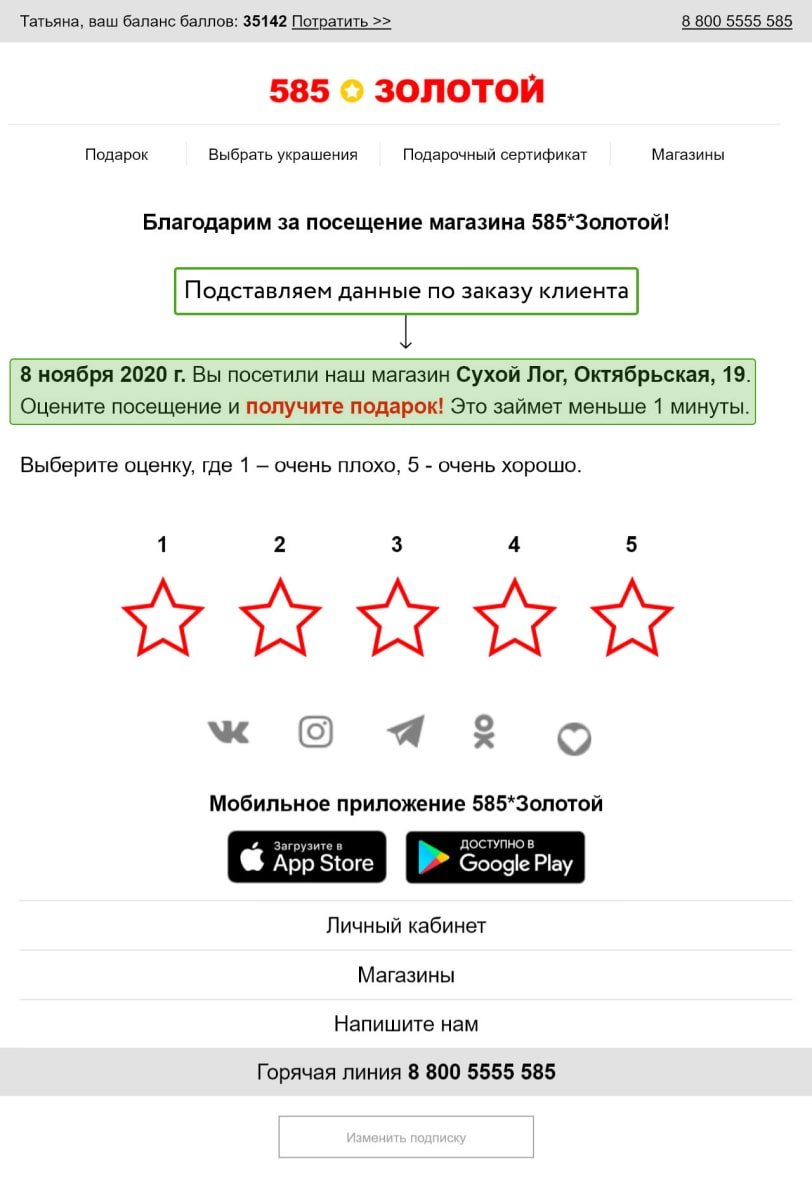
Ювелирная сеть «585*ЗОЛОТОЙ» собирает обратную связь от клиентов, чтобы улучшить работу конкретных магазинов или сети в целом. На основе отзывов меняют процесс обучения персонала, интерьеры магазина, ассортимент, информацию на ценниках.
Кроме того, опросы помогают компании решать проблемы клиентов без публичной огласки. Это положительно сказывается на репутации бренда.
На следующий день после покупки клиент получает письмо с просьбой оценить качество обслуживания
После того как клиент поставил оценку, открывается подробный опрос
После опроса клиент получает скидку на следующую покупку или подарок


Служба доставки еды Foodband обзванивала клиентов, чтобы выяснить, почему они уходят. Компания выяснила три главные причины:
- клиенты забыли о Foodband,
- их привлекли акции в других ресторанах,
- не было повода для заказа.
2. Предположить причину ухода и проверить ее с помощью АБ-тестов
Компания может догадываться о некоторых причинах оттока клиентов, но для подтверждения догадок нужно проводить АБ-тесты. Например, магазин предполагает, что покупатели уходят из-за высоких цен. Чтобы проверить гипотезу, одной части ушедших клиентов отправляют рассылку с промокодом на покупки, а второй — нет. Если клиенты, которым отправили промокод, возвращаются чаще, чем те, кому не отправили, гипотеза верна.
«Ароматный мир» проверил гипотезу о том, что промокоды могут вернуть клиентов. Для этого сегмент оттока разделили на три группы: первой не отправляли писем, а второй и третьей отправили письма с разным размером скидки. Клиенты, которые не получали писем, не совершали заказов. Получатели промокодов — совершали. Разница в конверсии между скидками — 5% и 7% оказалась незначительна. Это означает, что снижение цены помогает вернуть клиентов из оттока, но при этом размер скидки не имеет существенного значения.
3. Спросить у сотрудников, которые общаются с клиентами
Для этого можно устроить мозговой штурм или, наоборот, провести анонимный опрос сотрудников, которые непосредственно работают с клиентами. Бренд женской одежды Zarina даже предлагает сотрудникам отдела маркетинга провести день за работой в розничном магазине. Это помогает им напрямую пообщаться с клиентами, чтобы лучше понять аудиторию.
4. Мониторить отзывы о компании в интернете
Искать отзывы клиентов в публичном пространстве можно вручную или автоматически с помощью специальных сервисов.
Вручную можно искать по поисковым запросам с помощью инструментов «Яндекса» и Google*. Для этого достаточно ввести название компании или продукта в строку поиска. В социальных сетях удобно искать упоминания бренда по хештегам, которые проставляют пользователи в своих постах.
Результаты поиска в Google и ВКонтакте показывают все упоминания о Mindbox
Мнение
Mindbox работает в сегменте B2B, поэтому для себя мы определили следующую классификацию причин оттока:
- Внешние причины, на которые мы не могли повлиять, — переезд компании, закрытие проекта, смена команды на стороне клиента.
- Плохой сервис с нашей стороны — менеджер не смог помочь клиенту.
- Качество продукта не устроило клиента.
В сегменте B2C причины могут быть другими, например цена выше, чем в других магазинах.

Валентин Москалёв, customer group head Mindbox
Зачем контролировать отток клиентов
Если большое количество клиентов уйдет, компания вряд ли сможет компенсировать их потерю новыми клиентами, ведь средний чек покупки у старых клиентов выше на 33%, чем у новых.
Кроме того, вернуть прежнего покупателя обычно дешевле, потому что он уже знаком с продуктами компании. Вероятность продажи действующему клиенту — 60–70%, а новому — 5–20%.
2. Корректировать план по развитию компании
Ни один бренд не может быть идеальным для всех клиентов, поэтому отток есть всегда. Но его уровень часто зависит от действий компании. Если компания повышает цены, это закономерно ведет к увеличению оттока.
Принимая решение о каком-либо изменении, нужно анализировать отток в денежном эквиваленте. Это показывает, верным ли было решение.
Предположим, компания подняла цены. Если после этого прибыль увеличилась, то, скорее всего, повышение цен отсекло клиентов с маленькими чеками, а лояльные покупатели продолжили покупать. Это означает, что компания приняла верное решение. Если прибыль упала, то, возможно, высокая цена отпугнула постоянных покупателей, которые приносили основной доход. Следовательно, стоит подкорректировать ценовую политику, чтобы вернуть клиентов.
Как выделить сегмент оттока
Клиенты в оттоке — это клиенты, которые не совершают нужные компании действия определенное время.
Эти действия зависят от модели бизнеса, индустрии и продолжительности цикла покупки. Для торговых компаний действием может быть отсутствие покупок в течение двух месяцев. Для сервисов по подписке, таких как онлайн-кинотеатры, — отказ от оплаты ежемесячной подписки.
Временные границы оттока также зависят от индустрии. Если клиент полгода не покупал новый автомобиль, он не попадает в сегмент оттока, а если полгода не покупал крем для лица — это уже отток.
Вот кого считают оттоком наши клиенты:
| Компания | Сфера бизнеса и продукт | Каких клиентов относят к оттоку |
| Travelpayouts | Партнерская платформа по подписке: тревел-программы | Не авторизовывался в личном кабинете от 7 до 30 дней |
| OctaZone | Приложение для фитнес-тренировок по подписке | Отменил подписку на приложение |
| «Перекрёсток.Впрок» | Онлайн-супермаркет: продукты питания и товары для дома | Ничего не покупал и не открывал рассылки бренда в течение 30 дней |
| Orby | Офлайн- и онлайн-магазин одежды для детей и подростков | Ничего не покупал в течение 60 дней |
Мнение
В Mindbox помесячная подписка, поэтому клиент может уйти от нас в любой момент. Оттоком мы считаем клиентов, которые не продлили подписку на следующий месяц. Причиной может быть переход на другую платформу, создание собственного решения или закрытие проекта.
Валентин Москалёв, customer group head Mindbox
Как рассчитать уровень оттока клиентов — churn rate
Churn rate — это основная метрика, которую используют при анализе оттока. Она может быть выражена в количественном и процентном содержании.
Количественный churn rate
Метрика показывает количество ушедших клиентов за период. Для расчета нужны три цифры: число новых клиентов, число клиентов на начало и на конец периода.

Обычно churn rate рассчитывают за год, полугодие, месяц или неделю. Период зависит от цикла сделки, частоты покупок, размера бизнеса и его бизнес-модели. Онлайн-кинотеатрам по ежемесячной подписке стоит считать метрику раз в месяц, а магазину саженцев — раз в год.
Для примера рассчитаем годовой churn rate для интернет-магазина саженцев и семян:
5000 — количество клиентов в начале года
350 — новых клиентов за год
5200 — количество клиентов в конце года
Churn rate = 5000 + 350 − 5200 = 150, то есть за год компания потеряла 150 клиентов.
Churn rate в процентах
Метрика показывает соотношение клиентов, которые прекратили взаимодействие с компанией, и общего числа клиентов на начало периода.
Чтобы рассчитать метрику, понадобятся две цифры: количество клиентов в начале периода и в конце.

Для примера рассчитаем churn rate интернет-магазина саженцев и семян:
5000 — количество клиентов в начале года
5200 — количество клиентов в конце года
Churn rate = (5000 − 5200) ÷ 5000 × 100% = 4%.
Цифра означает, что компания в этом году потеряла 4% клиентов.
Как понять, что churn rate высокий
Сам по себе churn rate за один период неинформативен. Его нужно обязательно сопоставлять:
- с показателями своей компании за предыдущие периоды. Если в прошлом году компания удерживала 99% клиентов, а в этом 96% — значит, появились проблемы, из-за которых клиенты не возвращаются;
- с результатами других компаний в своей отрасли.
Средние показатели churn rate по отраслям, согласно статистике облачной платформы Recurly, за 2022 год:
| Отрасль | Средний CR |
| ИТ (разработка приложений, облачные платформы) | 4,75% |
| Цифровые СМИ: радио, телевидение, газеты и журналы | 6,42% |
| Образование | 7,22% |
| Розничная торговля | 7,55% |
| Профессиональные услуги | 6,59% |
| Здравоохранение | 6,03% |
Мнение
Мы считаем churn rate ежегодно и ежемесячно.
Годовая цифра помогает строить модель и прогнозировать цифры относительно прошлого года. Ежемесячный показатель помогает принимать решения более оперативно: давать клиентам обратную связь, получать ее, в целом понимать, что хорошо, что плохо.
Лучше всего анализировать churn rate в связке с выручкой. Бывает так, что метрика снижается вместе с ней. Это может быть связано с тем, что ушедшие клиенты покупали больше, чем те, кто остались. Чтобы это увидеть, можно сравнить выручку оставшихся и ушедших клиентов.
Валентин Москалёв, customer group head Mindbox
Как сократить отток клиентов
Если причины ухода известны, с ними можно бороться. Рассмотрим несколько способов.
1. Улучшить качество товаров и сервиса
Чтобы улучшить товары и процессы в компании, стоит прислушаться к отзывам клиентов. Только сам клиент знает точно, почему он перестает покупать.
Decathlon заменяет все товары с оценкой ниже 3,8. Если товар сделан за границей, его перестают закупать. Если товар сделан в России, его улучшают на производстве, чтобы он стал более качественным.
Мнение
В B2B обычно разбирают каждый конкретный случай ухода клиентов. В Mindbox мы анализируем случаи оттока по причине плохого сервиса. Это помогает придумать какие-то процессы, которые позволят в будущем этого оттока избежать. Возможно, это работа с конкретным человеком, или на уровне процессов, или с отдельной командой. Все зависит от ситуации и дополнительных причин, которые мы не проработали.
В B2C-сегменте обычно массово собирают отзывы клиентов и ранжируют причины ухода по популярности. Менять товары и процессы здесь надо, когда ими недовольны большинство покупателей.
Валентин Москалёв, customer group head Mindbox
2. Показать клиенту ценность продукта
Это обычно нужно компаниям, которые продают сложные и дорогие товары, например программное обеспечение. Цена на них может казаться клиенту завышенной, потому что он не видит для себя пользы за эти деньги. Показать ее можно с помощью видеороликов, рассылок или кейсов других клиентов.
Mindbox выпускает кейсы своих клиентов с достижениями в цифрах, чтобы потенциальные покупатели видели реальную выгоду от подключения платформы. Дополнительно для клиентов подготовлены видеоролики по использованию продукта, инструкция по настройке инструментов и курс по работе с платформой.
Кейсы клиентов Mindbox в журнале помогают потенциальным клиентам увидеть ценность продукта
Видеокурс Mindbox поможет маркетологам разобраться в функциях платформы

3. Снизить цены или предложить подарки за покупки
Иногда клиенты уходят, если в других магазинах цены дешевле. Для таких покупателей важна выгода — чтобы вернуть их, можно предложить скидки и промокоды. Если давать скидку невыгодно, можно предложить клиенту подарок к покупке.
Holodilnik.ru отправляет клиентам оттока письмо с кнопкой для получения промокода
Косметический бренд Teana дарит клиентам, которые не совершали покупки в течение 60 дней, промокод на бесплатный набор сывороток
FoodBand предлагает клиентам пиццу в подарок при заказе на минимальную сумму 650 рублей

4. Вовремя решать проблемы клиентов
Клиент вряд ли еще раз сделает заказ у бренда, если он однажды подвел его. Например, доставил букет в день рождения мамы с опозданием. К сожалению, такие ситуации случаются, поэтому компаниям стоит реагировать на них незамедлительно: извиняться, разбираться с проблемой, дарить скидку на следующий заказ. Это помогает оперативно снизить негативную реакцию клиентов, чтобы они не писали плохие отзывы в интернете.
Если плохие отзывы все же появляются, то компания должна отвечать на них. Это покажет, что она идет навстречу клиентам и ей можно доверять.
В сервисе доставки цветов Flor2U клиенты чаще всего жалуются на опоздание курьеров. Если в такой ситуации человек звонит в колл-центр, сотрудники решают его проблему: дарят промокод, предлагают привезти цветы в другое место. Если он пишет отзыв на сайтах-отзовиках, то компания тоже предлагает решение проблемы. Например, дарит баллы на следующие заказы или возвращает деньги за букет.

Flor2U благодарит клиентов за хорошие отзывы о своей работе

Flor2U извиняется перед недовольными клиентами: возвращает деньги за букет, даже если клиент его получил
5. Упростить процесс выбора товара
Причиной ухода может быть неудобный процесс покупки: запутанный поиск, сложная форма заказа. Если клиент не смог найти на сайте интересующий товар, то, скорее всего, он пойдет искать его в другие магазины. Узнать о недостатках процесса компания может, только спросив самих клиентов.
Ювелирная сеть Sunlight увеличила конверсию поисковика на сайте с 7,6% до 9,4% с помощью обратной связи от клиентов. Компания узнала, что клиенты часто пользуются сайтом как поисковиком, а не как каталогом. Они вбивают в поиск «недорогие кольца», «акции», «магазины в г. Краснодар» или специфические названия, например «бесконечность».
Компания учла эту информацию, и теперь, когда клиент вбивает в поиске «акция», его перебрасывает на страницу акций. Если ищет «бесконечность», ему выводятся товары из этой категории.
После запроса в поиске «зеленый бриллиант» открывается витрина украшений с бриллиантами и изумрудами. В правом углу появляется опрос об удобстве поиска
6. Напоминать клиентам о компании, но не спамить
Клиенты могут уходить, если забывают о бренде или если он слишком настойчиво предлагает новые товары. Чтобы клиенты не забывали о бренде, им стоит напоминать о себе: в email-рассылках, SMS и мессенджерах. Чтобы покупатели не раздражались, коммуникация не должна быть слишком частой. Кроме того, она должна быть полезной.
В издательстве МИФ есть правило: даже если человек подписался на все рассылки, ему отправляют не больше двух писем в неделю.
Чтобы выбрать, какое именно письмо отправить конкретному клиенту, компания использует сегментацию. Всех клиентов разделяют на группы на основе их действий: прошлые покупки, просмотры товаров, корзина, переходы по сайту. После этого для каждого покупателя подбирается письмо, которое будет интересно именно ему.
Это помогает компании ненавязчиво напоминать о себе, чтобы клиент не уходил за покупками к конкурентам. Например, клиенту, купившему книгу, отправляют письмо с мнением о ней и предлагают поделиться своим. Во втором письме отправляют рекомендации книг на похожие темы.

Механика, нацеленная на лояльность, хорошо себя показала: open rate в среднем составляет 40%
Мнение
В B2B- и B2C-сегментах разные подходы к работе с оттоком. В B2B работают более точечно и качественными методами. Например, обзванивают каждого клиента, чтобы выяснить причины ухода и предложить конкретные варианты решения проблем.
В B2C — методы количественные и массовые. Например, всем клиентам в оттоке отправляют промокод на скидку, чтобы мотивировать на новые покупки.
Валентин Москалёв, customer group head Mindbox
Чтобы вернуть клиентов из оттока, стоит сначала определить, какие клиенты считаются оттоком.
В Mindbox можно выделить сегмент оттока вручную и автоматически. Ручные фильтры можно настраивать почти по любым параметрам: дата последней покупки или открытия письма, последний визит на сайт. Для автоматической сегментации можно выгрузить встроенный RFM-отчет, который учитывает средние цифры: частоту, количество покупок и размер чеков клиентов. Отчет показывает, сколько покупателей находятся в оттоке, и выделяет их в отдельный сегмент для коммуникации.
Когда сегмент выделен, стоит подготовить для него персональные предложения: промокоды, подарки или просто напоминание о компании. Рассмотрим основные инструменты, в которых можно отправлять клиентам такие предложения.
Email-рассылка
В Mindbox очень гибкие настройки рассылки: по содержанию, частоте отправки и количеству писем. Можно создать одно письмо с промокодом, а можно сделать цепочку писем: в первом — напоминание о компании, а в последующих — скидка.
Рассылки могут быть ручными и автоматическими. Ручные чаще всего готовят под конкретное событие: Новый год, открытие магазина. Автоматические готовят один раз и настраивают так, чтобы они автоматически отправлялись в ответ на определенные действия клиентов. Например, «клиент не покупал в течение 60 дней» или «не открывал рассылки полгода». Обычно такие письма называют реактивационными.
FOAM отправляет клиентам оттока одно письмо со скидкой 15%. Конверсия в заказ по last cliсk — 0,3%
Онлайн-гипермаркет «Вам Свет» отправляет цепочку из четырех писем клиентам без покупок за последний год: в первом напоминает о бренде, во втором предлагает промокод, в третьем напоминает о промокоде, а в четвертом проводит опрос. Конверсия в заказ у писем — всего 0,04%, но они позволяют напомнить клиентам о себе через год


Руководитель группы прямых коммуникаций «Циан» Елена Полуянова говорит, что email-рассылки — это единственный инструмент, который помогает «достучаться» до оттока. Доставляемость мобильных пушей у неактивной аудитории быстро снижается, а email — история долгосрочная.
Push-уведомления
В Mindbox можно отправлять клиентам мобильные и веб-пуши. Мобильные пуш-уведомления клиент получит в своем мобильном приложении, а веб-пуши увидит в браузере при работе в интернете.
Их можно настраивать по времени отправки и по содержанию: заголовок, изображение, текст и ссылка для перехода на страницу предложения.
Foodband использует пуши для возврата клиентов, которые давно не покупали. Компании это удобно, потому что больше половины заказов клиенты делают через мобильное приложение.
В первом пуше — напоминание о компании
Если клиент не делает заказ, ему отправляют второй пуш со скидкой
SMS-рассылка
SMS-рассылка — эффективный способ «достучаться» до клиента, потому что их читают почти все: open rate SMS-сообщений — более 90%.
В Mindbox можно подставлять динамические данные из анкеты клиента, чтобы персонализировать SMS. Например, предложить клиенту скидку на товары, которыми он интересовался ранее.
Автохолдинг «Максимум» запустил SMS-рассылку для покупателей, которые ушли из центра, не оформив сделку. В каждое SMS подставлялась марка той машины, которую не купил клиент. Эта механика помогла вернуть 142 человека.
Коммуникация автохолдинга «Максимум» для тех, чьи сделки не состоялись
Анастасия Ломаченко, head of CRM & loyalty Crocus Group, советует учитывать немаленький бюджет SMS-коммуникации с клиентами. Если делается рассылка на миллион клиентов, ожидается отклик 20% — это 200 тысяч человек. На SMS для каждого клиента тратится 3 рубля. Всего компания тратит 3 миллиона на рассылку. Эти 3 миллиона должны окупиться за счет 200 тысяч откликнувшихся клиентов.
Ретаргетинг и персонализация рекламы
Персонализированная реклама настраивается в рекламных кабинетах «Яндекс. Директ», Google AdWords или в социальных сетях Faсebook*, Instagram*, «ВКонтакте», MyTarget.
Использовать персонализированную рекламу для возвращения клиентов из оттока можно при правильной настройке на нужный сегмент: «не покупали N месяцев», «не открывают рассылки N недель». Для выделения сегмента может не хватать информации по клиентам, которая есть в рекламном кабинете. Например, в кабинете может не быть истории офлайн-покупок клиента, поэтому бизнес будет «догонять» его нерелевантной рекламой. Решить проблему можно с помощью выгрузки сегментов из платформы клиентских данных — CDP.
Платформа Mindbox собирает всю историю действий клиента: офлайн- и онлайн-покупки, просмотры, интересы. Это позволяет ей сегментировать клиентов для настройки рекламы почти по любым критериям: частоте покупок, дате последней покупки, среднему чеку. Например, можно выделить клиентов без покупок с чеком выше среднего, чтобы настроить на них рекламу со скидкой. Выгружать эти сегменты в рекламные кабинеты можно вручную или автоматически с помощью модуля «Медиа».
После выгрузки в рекламном кабинете можно создать персонализированное рекламное сообщение для сегмента оттока. Например, с фотографиями просмотренных когда-то товаров.
Ресторанная сеть italy & co передает данные в рекламные кабинеты из CDP. Это позволяет находить клиентов в оттоке и показывать им рекламу для реактивации
Каскадные рассылки
В Mindbox можно настроить сценарии каскадных рассылок, чтобы сэкономить бюджет на возврат клиентов. Первое письмо отправляют всем клиентам в самом дешевом канале — email, а последнее — в самом дорогом, SMS. Это позволяет охватить тех клиентов, которые не открывают рассылки, потому что SMS читают почти все.
Кроме того, можно включить в каскад рекламные объявления. Это довольно дорогой канал привлечения, поэтому использовать его лучше вместо SMS, если номера телефона клиента нет в базе.

Пример каскада: отправка email → пуш → SMS либо реклама
Интернет-магазин FOAM во время больших распродаж использует каскады, чтобы «достучаться» до большего числа клиентов. Тех, кто не открывает email, «догоняют» с помощью SMS:
Email-рассылка об акции Beauty Rhythm Fest
SMS об акции Beauty Rhythm Fest

Как запустить реактивацию оттока
Перед запуском реактивации стоит рассчитать churn rate и сравнить его со средними показателями по индустрии, чтобы понять, к чему стремиться. В дальнейшем — отслеживать churn rate постоянно, чтобы анализировать отдачу от реактивационных действий.
Работать с оттоком лучше сразу в двух направлениях: улучшение товаров и процессов внутри компании и выстраивание коммуникации с клиентами.
Для улучшения товаров и процессов можно собирать обратную связь от клиентов, мониторить отзывы в интернете и устраивать мозговые штурмы среди сотрудников. Эта обратная связь может также стать источником идей для коммуникаций.
Чтобы запустить коммуникации для клиентов в оттоке в B2C-сегменте, нужно:
- Выделить сегмент клиентов, которых стоит возвращать. Можно работать со всеми клиентами без покупок, а можно выделить более мелкий сегмент — например, клиенты без покупок с чеком выше среднего. Все зависит от сферы бизнеса и ее особенностей.
- Подготовить для выбранных клиентов персонализированные предложения.
- Использовать каскадные рассылки, чтобы охватить больше клиентов и сэкономить на дорогих каналах общения.
В B2B-сегменте стоит провести интервью с клиентом, чтобы понять, можно ли решить проблему альтернативным способом. Если нет, то важно постараться сохранить хорошие отношения с клиентом и договориться о следующих шагах, например звонке через полгода.
* Принадлежит Meta, деятельность которой признана экстремистской и запрещена на территории России.