Регистр сведений: чем отличаетс Ресурс от Реквизита? |
Я |
29.05.08 — 11:04
оба могут иметь любой тип данных, в построении запросов тоже разницы не заметил.. в чем разница?

1 — 29.05.08 — 11:05
По измерениям идет контроль уникальности.
2 — 29.05.08 — 11:06
я не про измерения спрашиваю — с ними то как раз все понятно
3 — 29.05.08 — 11:13
(29) срезы
4 — 29.05.08 — 11:15
что срезы? также все доступно..
5 — 29.05.08 — 11:16
Цитата из «проф. разработки»:
«Хотелось бы особо отметить, что деление информации регистра на реквизиты и ресурсы — элемент общего подхода. И хотя технологически хранение информации ресурсов и реквизитов регистра сведений существенно не различаетс, правильное «отнесение» разработчиком данных к ресурсам или к реквизитам позволяет впоследствии быстро отличить, что является «функцией» регистра, а что комментирует запись.
Строго говоря, это один из ключевых моментов организации разработки в 1С:Предприятии — деление структуры метаданных по ролям, исполняемых конкретными объектами в прикладном решении, а не только по технологическому устройству.»
6 — 29.05.08 — 11:17
в реквизит записывается всмопогательная инфомарция.
7 — 29.05.08 — 11:18
тяжелое наследие структуры регистров накопления…
8 — 29.05.08 — 11:20
(2) невнимательность, быстро читал 
(7) верно, для унификации просто оставлено.
9 — 29.05.08 — 11:21
ну, для периодических то разница все-таки есть, как верно сказал (3)…
10 — 29.05.08 — 11:22
ну значит я все верно понял, что механизм внутри один, просто сделано типа дляя удобства..
11 — 29.05.08 — 11:22
(9) в чем разница? при построении запрос по срезам доступно все также
12 — 29.05.08 — 11:22
(10) нет конечно.
13 — 29.05.08 — 11:24
(11) из среза можно достать значение реквизита? Наверное я что-то пропустил…
14 — 29.05.08 — 11:24
Разделение идет больше логическое, особенно, если регистр плоский (не периодический), учитывая, что период и регистратор — это те же измерения, то основное отличие в том, что совокупность измерений составляют аналог «первичного ключа» — это основное отличие от плоского (не иерархического) справочника.
15 — 29.05.08 — 11:27
(13)
ВЫБРАТЬ
ИсполнениеБюджетаСрезПоследних.Сумма КАК Сумма,
ИсполнениеБюджетаСрезПоследних.ОснованиеПлатежа КАК ОснованиеПлатежа,
ИЗ
РегистрСведений.ИсполнениеБюджета.СрезПоследних КАК ИсполнениеБюджетаСрезПоследних
Сумма — ресурс, ОснованиеПлатежа — реквизит
16 — 29.05.08 — 11:27
(4) Если РС периодический, то добавленный вручную реквизит (не служебный, а именно добавленный) не попадет в виртуальную таблицу срезов
17 — 29.05.08 — 11:28
(14) еще раз, про измерения речи не идет
18 — 29.05.08 — 11:30
(16) и что, в выборке будет пусто по этой колонке?
19 — 29.05.08 — 11:30
(16) Хотя нет, попадет
20 — 29.05.08 — 11:30
(15) и что выдает в качестве реквизита? Последнее значение реквизита?
21 — 29.05.08 — 11:31
(14) сорри, невнимателен. Как до утки на 3 сутки.
22 — 29.05.08 — 11:33
(20) ну смотря какой срез, а так конечно..
23 — 29.05.08 — 11:34
(22) странно. Тогда, сдается мне действительно ничем не отличается…
24 — 29.05.08 — 11:35
(23) вот мне после экспериментов и стало интересно, в чем же разница.. может я что-то упустил.. а нет, оказывается все просто на уровне разделения понятий..
Mitriy
25 — 29.05.08 — 11:39
(5) судя по всему — специально для того, чтобы при сдаче на спеца было к чему придраться, если больше не к чему…
Вопрос Чем реквизит отличается от измерения — это понятно всем. А вот чем реквизит отличается от ресурса?
Регистр сведений – это вырожденный случай регистров. Поэтому у него «не все так», как у «настоящих» регистров (накопления, бухгалтерии, расчета). И чтобы не путаться дальше будем рассматривать все в несколько в упрощенном виде.
Сначала посмотрим, как работает «настоящий» регистр, регистр накопления.
Регистр простой, два измерения, один ресурс и один реквизит (рис. 1).

Допустим, в регистре есть четыре записи (рис. 2).

Это – основная таблица регистра, т.е. таблица, содержащая записи, которые были добавлены в регистр.
Вы можете получить записи этой таблицы и, естественно, отобрать их по любому из существующих полей (рис. 3).

«Функция» регистра накопления, грубо говоря, заключается в том, чтобы суммировать значения ресурсов. Причем это суммирование выполняется для всех различных значений измерений. То есть, если вы попросите «функцию» этого регистра, то получите следующий результат (рис. 4).

То есть значения ресурсов для записей, содержащих одинаковые значения измерений (в данном случае Значение1 и Значение2) будут просуммированы (9 + 1 = 10).
Понятно, что когда вы получаете функцию, невозможно получить какие-либо реквизиты, потому что, например, непонятно, как можно «сложить» Заметка99 и Заметка1?. Можно только «развернуть функцию», и посмотреть, из каких записей она сложилась, какие у этих записей реквизиты. Но сам результат «функции» не содержит информации о каждой из записей (рис. 5).

Поэтому реквизиты – это некоторая вспомогательная информация, которая нам не интересна, когда мы получаем «функцию» регистра. Но эта информация может нам понадобиться, если мы захотим посмотреть, из каких записей сложился результат этой «функции».
Теперь посмотрим на регистр сведений. Возьмем периодический регистр сведений с такой же структурой и такими же записями. Его основная таблица будет выглядеть следующим образом (рис. 6).

«Функцией» периодического регистра сведений является получение наиболее ранних или наиболее поздних записей, на некоторую дату по различным сочетаниям значений измерений. Например «функция» этого регистра на 29 число будет выглядеть следующим образом (рис. 7).

То есть для уникального сочетания значений измерений будет выбрана одна из существующих записей основной таблицы, в отличие от регистра накопления, в котором результатом функции являлась запись, не существующая в основной таблице (рис. 8).

Таким образом, «функция» периодического регистра сведений по своей сути отличается от «функций» «настоящих» регистров. «Функция» «настоящих» регистров возвращает некоторую информацию о совокупности записей, а «функция» регистра сведений заключается в том, чтобы указать на одну из имеющихся записей. Понятно, что в результате такого «указания» мы можем видеть и значение реквизита. То есть с любым результатом функции будет однозначно связано одно из значений реквизита, а не несколько значений реквизита, как для регистра накопления. Поэтому, вычисляя функцию периодического регистра сведений, можно, помимо значений измерений, как у «настоящих» регистров, задать и значение реквизита.
Если же рассматривать непериодический регистр сведений, то у него вообще нет «функции». Можно только записать данные в его основную таблицу, и прочитать их. Несмотря на это он так же имеет измерения, ресурсы и реквизиты. Потому что данные в этот регистр заносятся по тем же правилам, как и во все другие регистры: не может быть двух записей, с одинаковыми значениями ключевых полей (измерений, в данном случае).
Первоисточник
Любой регистр можно представить в виде функции, возвращающей некоторое значение (значения) в зависимости от переданных параметров (параметра).
Измерения регистра описывают параметры этой функции.
Возвращаемое значение (значения) функции описываются ресурсами регистра.
Данные заносятся в регистр путем добавления записей. Реквизит — это просто некоторое поле, содержащее дополнительную информацию о записи.
При работе с регистром вы можете получать значения ресурсов, соответствующие значениям измерений, то есть «реализовывать» функцию, которую представляет собой регистр.
Или вы можете выбирать некоторые записи, содержащиеся в регистре, соответствующие значениям измерений или реквизитов. То есть анализировать исходные данные, «от которых» раcсчитывает свою функцию регистр.
Для «настоящих регистров» (накопления, бухгалтерии, расчета) получать значения ресурсов, указывая реквизиты, нельзя. И получив значения ресурсов (то есть «вычислив функцию регистра»), вы не сможете увидеть реквизиты.
Next Post
-
v8
-
Программисту 1C
Вт Май 18 , 2010
Как в языке запросов 1С используются временные таблицы. Что такое временные таблицы. Что такое виртуальные таблицы. В одном из последних релизов платформы 8.1 появилась возможность использовать в запросах временные таблицы. Что это такое и как их можно использовать? Рассмотрим пример, с которым наверное многие из Вас сталкивались — а именно […]
В чем принципиальное отличие ресурса от реквизита в регистре сведений?
в ресурсах хранятся только числовые данные
Ресурс — это данные, которые хранятся на пересечении измерений. Реквизит — это доп. информация о каждой записи (движении). Отличия чувствуются для периодических регистров сведений. Ресурсы возвращаются методами СрезПервых и СрезПоследних (а также вирт. таблицами в запросах). Хотя в запросе можно и реквизиты прочитать. Там возвращаются первые/последние записи.
Т.е. для непериодического регистра никаких различий нет? А для периодического раличия _только_ в возможности использования методов СрезПервых и СрезПоследних? (при использовании запросов — «основного средства извлечения данных» — исчезает и эта разница).
Вы довели мою идею до абсурда. Уберите все предикаты категоричности.
щаз на сцену выйдет абсурд …
Прошу прощения – погорячился. И убираю предикаты категоричности: Какие еще различия имеются между ресурсами и реквизитами периодического регистра сведений кроме результатов методов СрезПервых и СрезПоследних? Имеются ли различия между ресурсами и реквизитами непериодического регистра сведений?
Тэги:
Комментарии доступны только авторизированным пользователям
В этой статье мы познакомимся с очень интересным объектом метаданных конфигурации 1С – регистром сведений. Регистры сведений применяются для хранения различной информации, которая может использоваться в прикладной задаче. Информация в регистре сведений хранится в определенных разрезах, которые называются измерениями, а еще она может изменяться во времени.
Регистры сведений, информация которых изменяется во времени, называются Периодическими, а иначе эти регистры называют Непериодическими. Периодичность может быть разной, может быть периодичность в секунду, минуту, час и т.д. максимум — год.
Основное предназначение регистров сведений в том, что в них должны храниться показатели аналитики. Например, у нас есть задача хранить виды топлива (АИ-92, АИ-95 и т.д.), но также и цену на этот вид топлива. Как это удобное всего организовать. Однозначно сами виды топлива необходимо хранить в каком-то справочнике. Так его и назовем – вид топлива. Но где же хранить цену на этот вид топлива? Самое первое решение в реквизите справочника.

Очевидно, такое решение имеет место, если цена у нас ни когда не изменяется. Но в жизни такое редко случается, поэтому если мы так сделаем, то возникнет необходимость каждый раз изменять элемент справочника при изменении цены. В принципе, почему бы и нет. Но, если мы еще добавим новый разрез цены – поставщик топлива: у одного и того же вида топлива может быть разная цена для разных поставщиков, то хранение цены в реквизите справочника станет принципиально не возможной: мы не будем знать, к какому поставщику относиться эта цена.
Для решения этих задач служит специальный объект конфигурации — регистр сведений. В этом регистре сведений можно создавать записи, в которых будет указано, что для такого-то вида топлива, для такого-то поставщика устанавливается такая-то цена.
Сейчас мы и решим эту маленькую прикладную задачу: в нашей конфигурации есть два справочника «Виды топлива» и «Поставщики топлива»

Необходимо организовать возможность хранения цены для каждого вида топлива с учетом поставщиков. Для этого в конфигураторе 1С создадим новый регистр сведений ЦеныНаТопливо.

На закладке Основные установим имя и синоним. Все остальное оставим как есть.

Теперь на закладке данные создадим два измерения – ВидТоплива и ПоставщикТоплива, типы которых ссылки на соответствующие справочники.


У обоих измерений поставим флаг – Ведущее. Это значит, что если мы удалим элемент справочника, который указан в какой-то записи регистра сведений, то эта запись удалиться автоматически. Так же есть одно интерфейсное следствие этого флага: если флаг установлен, то в форме элемента справочника мы сможем посмотреть на записи этого регистра для этого элемента.
Установим для каждого измерения этот флаг.


У нас непериодический регистр, и в нем два измерения ВидТоплива и ПоставщикТоплива это значит, что мы не сможем создать две записи с одинаковыми значениями полей ВидТоплива и ПоставщикТоплива. Программа выдаст ошибку. Что и разумно – не может быть две разных цены на один и тот же вид топлива у одного и того же поставщика. А если может, то это значит, что необходимо добавить еще один разрез (например, база поставщика).
Кроме измерений у регистра сведений существуют Ресурсы и Реквизиты. Ресурс должен хранить основную информацию регистра сведений, т.е. те данные, ради которых он создан, а Реквизит содержит дополнительную второстепенную информацию о записи.
Мы создадим ресурс – Цена (тип число 10,2).

И всё. Сохраним конфигурацию и откроем этот регистр сведений и заведем какую-нибудь запись.

Если мы сейчас попробуем создать запись с точно таким же набором измерений, то возникнет ошибка: «Запись с такими ключевыми полями существует».


И последний момент: поскольку мы у измерения ВидТоплива установили флаг «Ведущее», то у элемента справочника ВидыТоплива появилась команда на открытие регистра сведений «Цена на топливо»

Если мы в управляемом приложении 1С перейдем по этой команде, то увидим все цены для нашего вида топлива.

Продолжение темы регистров сведений читайте в следующих статьях:
Периодический регистр сведений 1С
Подчиненный регистр сведений 1С
Изучайте основы конфигурирования в 1С и учитесь программировать в «1С: Предприятии» с помощью моих книг: «Программировать в 1С за 11 шагов» и «Основы разработки в 1С: Такси»
 Книга «Программировать в 1С за 11 шагов»
Книга «Программировать в 1С за 11 шагов»
Изучайте программирование в 1С в месте с моей книги «Программировать в 1С за 11 шагов»
- Книга написана понятным и простым языком — для новичка.
- Книга посылается на электронную почту в формате PDF. Можно открыть на любом устройстве!
- Научитесь понимать архитектуру 1С;
- Станете писать код на языке 1С;
- Освоите основные приемы программирования;
- Закрепите полученные знания при помощи задачника;
Книга «Основы разработки в 1С: Такси»

Отличное пособие по разработке в управляемом приложении 1С, как для начинающих разработчиков, так и для опытных программистов.
- Очень доступный и понятный язык изложения
- Книга посылается на электронную почту в формате PDF. Можно открыть на любом устройстве!
- Поймете идеологию управляемого приложения 1С
- Узнаете, как разрабатывать управляемое приложение;
- Научитесь разрабатывать управляемые формы 1С;
- Сможете работать с основными и нужными элементами управляемых форм
- Программирование под управляемым приложением станет понятным
Промо-код на скидку в 15% — 48PVXHeYu
Если Вам помог этот урок решить какую-нибудь проблему, понравился или оказался полезен, то Вы можете поддержать мой проект, перечислив любую сумму:
можно оплатить вручную:
Яндекс.Деньги — 410012882996301
Web Money — R955262494655
Вступайте в мои группы:
Вконтакте: https://vk.com/1c_prosto
Фейсбуке: https://www.facebook.com/groups/922972144448119/
ОК: http://ok.ru/group/52970839015518
Твиттер: https://twitter.com/signum2009
Основная идея публикации — собрать в одном месте информацию о внутреннем устройстве такой абстрактной сущности, как «Регистр сведений 1С» и ответить на ряд вопросов:
Что происходит при записи регистра в различных режимах? Что такое на самом деле «СрезПервых» и «СрезПоследних»? Как оптимально выбрать структуру регистра?
Это та информация, владея которой, начинаешь лучше понимать как это работает и как правильно использовать регистры сведений.
Публикация имеет характер исследования, поэтому подробная и объемная. Кто не любит много букв — можно начать с выводов, они специально выделены в содержании.
Для тех, кто только делает первые шаги в 1С: не смотря на подробность изложенной информации и её справочно-обучающую интонацию, тут нет самых азов. Подразумевается, что читатель уже имеет базовое понимание и практику конфигурирования в 1С. Статья не учит как программировать, но она помогает найти ответы на вопросы «А как правильно и почему именно так?».
Для тех, кто все это знает: возможно, у вас есть свои выводы и своя точка зрения, делитесь ими в коментах. Спасибо!
Содержание:
1. Архитектура регистра на уровне СУБД.
— индексы непериодического, независимого регистра сведений
— индексы непериодического, подчиненного РС
— индексы периодического, независимого РС
— индексы периодического, подчиненного РС
— индексы периодического РС с периодичностью «По позиции регистратора»
— индексы таблицы итогов среза первых и среза последних
Выводы.
2. Разбираемся с записью регистров
Независимые регистры сведений.
— запись «по умолчанию»
— запись без замещения
— запись без проверок
Менеджер записи
Подчиненные регистры сведений.
— запись «по умолчанию»
— запись с замещением и признаком обмена данными
— запись без замещения
— запись без замещения с признаком обмена данных
— подчиненный РС с периодичностью по позиции регистратора
Промежуточные выводы. Сравниваем 8.2 и 8.3, независимые и подчиненные регистры.
Регистры сведений с итогами.
— запись с замещением («по умолчанию»)
— запись без замещения
подчиненные регистры с таблицей итогов
Выводы по регистрам с итогами
3. Как работает СрезПоследних (СрезПервых) в запросе
срез последних на языке 1С для регистра с периодичностью <> по позиции регистратора
срез последних на языке 1С для регистра с периодичность «По позиции регистратора»
самая частая ошибка при фильтрации среза
отличия 8.2 и 8.3 для запросов среза
когда используется таблица итогов
Выводы
Заключение
Все примеры будут даны для версий 1С 8.3.6 — 8.3.8. На 8.2.19 логика на 99% совпадает с работой 8.3, есть несколько отличий, про которые обязательно упомяну.
Работа платформы с регистрами сведений несколько раз менялась. 8.3 стала более оптимальной и как бы мне не хотелось «потыкать палочкой» в 8.1 и в ранние версии 8.2, дабы показать как все было плохо, решил этого не делать. Кому станет любопытно «как было» — получит мотивацию изучить вопрос.
Вводная.
Основное назначение регистров сведений — хранить информацию НЕ ссылочного типа в разрезе комбинации измерений и, как частный случай, хранить изменяемые во времени значения. По большому счету, в регистре можно хранить что угодно, но получить ссылку на саму запись регистра и сохранить её (ссылку на запись) в реквизитах другого объекта, например справочника, уже не получится. Собственно отличие ссылочных типов от не ссылочных — это один из краеугольных камней 1С т.ч. кто прогуливал — учим мат часть.
1. Архитектура регистра на уровне СУБД.
Спустимся с уровня абстракции «конфигуратор» на уровень «СУБД» и вспомним, в очередной раз, что все данные базы хранятся именно в СУБД. Это может быть файловая база (тут в роли СУБД платформа 1С), PosgreSQL, IBM DB2, Oracle и MS SQL Server.
Регистр сведений на уровне СУБД представляет собой обычную плоскую таблицу, в которой колонки это наши измерения, ресурсы и реквизиты, а строки — записи регистра. Узнать какая таблица СУБД соответствует конкретному регистру, можно используя метод платформы ПолучитьСтруктуруХраненияБазыДанных(), либо воспользоваться одной из множества обработок, уже опубликованных на INFOSTART.
Отличия ресурсов от реквизитов на уровне хранения данных отсутствуют, это сугубо логическое разделение. Предполагается, что реквизит это некая дополнительная информация, а ресурс — основное значение, которое нам и требуется хранить в разрезе комбинаций измерений.
Отличие измерений от ресурсов и реквизитов в том, что измерения в полном составе присутствуют во всех индексах таблицы. Порядок следования измерений в индексе такой же, как в конфигураторе. Если у ресурса (реквизита) установлено свойство «Индексировать», то будет создан индекс, в котором на первом месте этот ресурс (реквизит), а далее все наши измерения. Установить свойство «Индексировать» можно и у измерения, в этом случае будет создан дополнительный индекс, в котором на первом месте «проиндексированное» поле, а следом за ним оставшиеся измерения.
До версии 8.2.15 непериодический регистр сведений не имел кластерного индекса, начиная с этой версии, платформа создает кластерный индекс, состоящий из измерений (в том порядке, как они заданы в конфигураторе).
Версия 8.3 принесла еще несколько важных изменений:
- для периодических регистров кластерным стал индекс, в котором сначала следуют все измерения, а на последнем месте колонка Период (в 8.2 кластерным будет являться индекс, в котором на первом месте стоит Период, а затем перечислены все измерения);
- появились физические таблицы итогов для хранения среза первых и среза последних. Создавать или нет эти таблицы — решает разработчик, установив соответствующее свойство в конфигураторе.
Давайте посмотрим, какие индексы создаются в зависимости от версии платформы, периодичности и подчиненности регистра. Сразу оговорюсь, что информация на ИТС не точна в части кластерных индексов, верить написанному ниже:
Непериодический, независимый регистр
| Индекс | Условие и описание | Кластерный |
| Измерение1 + [Измерение2 +…] | Есть хоть одно измерение регистра. Индекс, включающий все измерения в том порядке, в котором они заданы при конфигурировании. | начиная с 8.2.15 и 8.3 |
| ИзмерениеN + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не первое и не единственное измерение. Первое поле — ИзмерениеN, затем все остальные измерения в том порядке, в котором они заданы при конфигурировании. | — |
| Реквизит + Измерение1 + [Измерение2 +…] | Реквизиту «Реквизит» задано свойство «Индексировать». Индекс, в котором первое поле — Реквизит, затем все измерения в том порядке, в котором они заданы при конфигурировании. | — |
| Ресурс + Измерение1 + [Измерение2 +…] | Ресурсу «Ресурс» задано свойство «Индексировать». Индекс, в котором первое поле — Ресурс, затем все измерения в том порядке, в котором они заданы при конфигурировании. | — |
| SimpleKey (удалено в 8.3.3 и старше) | Количество измерений больше одного. Используется для обхода регистра при реструктуризации, а также для выборки записей с использованием оптимального порядка обхода. | — |
Непериодический, подчиненный регистр
| Индекс | Условие и описание | Кластерный |
| Регистратор + НомерСтроки | Создается всегда. | Да, всегда |
| Измерение1 + [Измерение2 +…] | Есть хоть одно измерение регистра. | — |
| ИзмерениеN + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не первое и не единственное измерение | — |
| Реквизит + Измерение1 + [Измерение2 +…] | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Измерение1 + [Измерение2 +…] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
| SimpleKey (удалено в 8.3.3 и старше) | Количество измерений больше одного. Используется для обхода регистра при реструктуризации, а также для выборки записей с использованием оптимального порядка обхода. | — |
Периодический, независимый регистр
| Индекс | Условие и описание | Кластерный |
| Период + [Измерение1 + …] | Создается всегда. | для 8.2 |
| Измерение1 + [Измерение2 +…] + Период | Есть хоть одно измерение регистра. | для 8.3 |
| ИзмерениеN + Период + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не единственное измерение. | — |
| Реквизит + Период + [Измерение1 + …] | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
Периодический, подчиненный регистр
| Индекс | Условие и описание | Кластерный |
| Регистратор + НомерСтроки | Создается всегда. | — |
| Период + [Измерение1 + …] + [Активность]* | Создается всегда. | для 8.2 |
| Измерение1 + [Измерение2 +…] + Период + [Активность]* | Есть хоть одно измерение регистра. | для 8.3 |
| ИзмерениеN + Период + Измерение1 + [Измерение2 +…] + [Активность]* |
Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не единственное измерение. |
— |
| Реквизит + Период + [Измерение1 + …] + [Активность]* | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
* только для 8.3
Периодический, с периодичностью «По позиции регистратора»
| Индекс | Условие и описание | Кластерный |
| Период + Регистратор + НомерСтроки | Создается всегда. | для 8.2 |
| Регистратор + НомерСтроки | Создается всегда. | — |
| Измерение1 + [Измерение2 + …] + Период + Регистратор + НомерСтроки + [Активность]* | Есть хоть одно измерение регистра. | для 8.3 |
| Измерение + Период + Регистратор + НомерСтроки + [Активность]* | Измерению «Измерение» задано свойство «Индексировать». | — |
| Реквизит + Период + Регистратор + НомерСтроки + [Активность]* | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + Регистратор + НомерСтроки | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
* только для 8.3
Индексы таблицы итогов среза первых и среза последних. Только для 8.3.
| Индекс | Условие и описание | Кластерный |
| Измерение1 + [Измерение2 + …] | Есть хоть одно измерение регистра. | — |
| Реквизит + [Измерение1 + …] | Реквизиту «Реквизит» задано свойство «Индексировать» | — |
| Ресурс + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать» | — |
Замечание. Если вы в своей базе видите отличия от того, что приведено в таблицах, то, скорее всего, вы работаете в режиме совместимости с 8.2. Так же при переходе с 8.1 на 8.2 структура индексов сама не меняется, необходимо сделать реструктуризацию.
Можно сказать, что в 8.3 структура индексов продумана лучше — в индексы добавлена «Активность», использование в качестве кластерных индексов вида «Измерение1 + [Измерение2 +…] + Период» снижают ресурсоемкость запросов (это ни в коем разе не панацея, но ниже рассмотрим примеры запросов и еще раз затронем тему эффективности индексов). При этом к 8.3 есть и вопросы, например не понятно, почему при индексировании ресурса в периодическом регистре в индекс не добавляется «Активность» и почему нет кластерного индекса в таблицах срезов.
Выводы:
- Порядок измерений, заданный в конфигураторе, влияет на структуру индексов и, как следствие, может влиять на скорость выборки данных. Дело в том, что индекс «не работает» если нет фильтра по первому его полю, при этом поля, по которым накладываются фильтры, должны идти в индексе друг за другом.
Например, есть непериодический, независимый регистр со следующими измерениями: Организация, Склад, Номенклатура. В СУБД получаем таблицу с одним индексом Организация + Склад + Номенклатура. Теперь рассмотрим различные варианты запросов к этому регистру:
- запрос с условием отбора только по Номенклатуре …ГДЕ Номенклатура = &Номенклатура — индекс «работать» не будет.
- запрос с фильтром …ГДЕ Склад = &Склад И Номенклатура = &Номенклатура — индекс так же не будет «работать» т.к. и в том и в другом случае нет отбора по Организации.
- запрос с отбором …ГДЕ Организация = &Организация И Номенклатура = &Номенклатура — индекс будет работать, но не эффективно — все данные по Организации будут получены быстро, но потом все они будут просканированы (построчно просмотрены), проверяя та ли Номенклатура в этой строке. А т.к. организаций обычно всего одна, а Номенклатур очень много, то прочитаны будут все строки регистра.
Для этого набора запросов самым оптимальным будет поменять местами измерения Организация и Номенклатура (получим индекс Номенклатура + Склад + Организация), тогда вопрос с эффективным использованием индекса будет только для запроса …ГДЕ Организация = &Организация И Номенклатура = &Номенклатура. Если в базе только одна организация, то индекс можно назвать подходящим т.к. условие по номенклатуре уже вернет малое число строк, которые очень быстро проверятся на соответствие условию по организации. Если организаций много, то правильным решением будет дополнительно создать индекс Организация + Номенклатура [+ Склад].
Итоговый универсальный вариант: измерения в порядке следования Номенклатура, Склад, Организация, у измерения Организация ставим свойство Индексировать.
Из этого примера можно сделать очень интересный вывод — спроектировать оптимальную архитектуру регистра можно только при известном пуле запросов, которые будут к нему обращаться, и понимании как будут распределяться данные!
- Стремитесь к тому, что бы кластерный индекс регистра покрывал потребности самых частых запросов. Кластерный индекс содержит в себе все данные таблицы, для простоты понимания можно сказать, что кластерный индекс это надстройка над данными. Некластерный содержит только значения тех полей, из которых он состоит. Например, есть периодический независимый регистр сведений «ЦеныТоваров» с измерениями Товар + ВидЦены и ресурсом Цена. Самая частая задача — зная товар и вид цены получить актуальную цену товара, т.е. по значениям измерений получить значение ресурса «Цена». Для этой цели идеально подходит типовой индекс «Товар + ВидЦены + Период». В 8.3 этот индекс будет кластерным и значение цены будет получено сразу. В 8.2 этот индекс некластерный, что означает необходимость дополнительно «залезть» в таблицу данных и получить нужное значение.
- Не желательно создавать регистры с большим числом измерений. Обратная сторона индексов — накладные расходы на их содержание. Чем «легче» индекс, т.е. чем меньше полей в него входит и чем меньше места занимают данные в этих полях, тем быстрее происходит запись и поиск данных. Это не стоит расценивать как табу, задачи бывают разные, но если вы проектируете регистр, для которого важна быстрая вставка больших объемов данных, то старайтесь снизить и число измерений и число индексов в этой таблице.
Особо отмечу, что индекс не может содержать более 16 полей и периодический регистр с 16ю измерениями платформа усечет поля в индексах — создаст без последнего измерения: [Период + Измерение1 + … + Измерение15], а второй индекс не будет содержать поле Период: [Измерение1 + … + Измерение16]. Работа с таким регистром может вызвать проблемы со скоростью получения данных, хотя с прикладной точки зрения ошибок не будет. Стоит учитывать составные типы, одно измерение составного типа в СУБД будет состоять из нескольких полей (в самом жестком случае — до 7 полей на одно измерение).
Знания что такое индекс, как он работает, чем отличается кластерный от не кластерного — очень важны, кто не уверен в своих силах, могу посоветовать доклады Дмитрия Короткевича.
#Содержание
2. Запись регистра.
Казалось бы, простая запись регистра, в чем тут разбираться? Но у набора записей существует три режима записи, да еще и менеджер записи добавляется т.ч. «будем посмотреть».
Вводные: база на 8.3 (проверено на 8.3.6 — 8.3.8), несколько регистров сведений и MS SQL Server. Разбираться, что происходит в СУБД, будем путем трассировок запросов (Profiler).
Независимые регистры сведений.
Структура регистра:
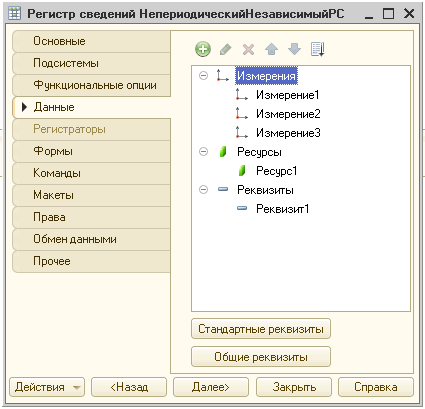
Выполняемый код 1С:
ОбъектРегистр = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
СтруктураОтбора = Новый Структура();
СтруктураОтбора.Вставить("Измерение1", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение2", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение3", Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Измерение1.Установить(СтруктураОтбора.Измерение1);
ОбъектРегистр.Отбор.Измерение2.Установить(СтруктураОтбора.Измерение2);
ОбъектРегистр.Отбор.Измерение3.Установить(СтруктураОтбора.Измерение3);
ЗаполнитьЗначенияСвойств(ОбъектРегистр.Добавить(), СтруктураОтбора);
ОбъектРегистр.Записать(Замещать);Независимые РС. Режим 1. Запись «по умолчанию».
// (!)Режим загрузки при замещении не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <Любой>;
// ...
ОбъектРегистр.Записать(Истина);Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Удаление записей по значению установленного отбора записываемого набора. Обращаю внимание, что этот запрос выполняется всегда.
DELETE FROM T1 FROM dbo._InfoRg288 T1 WHERE T1._Fld289 = @P1 AND T1._Fld290 = @P2 AND T1._Fld291 = @P3
если установить отбор только на Измерение1 и Измерение2, то условие сократиться до <<…WHERE T1._Fld289 = @P1 AND T1._Fld290 = @P2 >>, если отборы не установлены — удаляться все записи.
1.3. Вставляем запись в таблицу.
INSERT INTO dbo._InfoRg288(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей
1.4. Фиксируем транзакцию
COMMIT TRANSACTION
Как видим — все достаточно просто, сначала удаляем записи, затем вставляем. Кстати, в 8.2 поведение аналогичное. В чем минус? Только в том, что удаление происходит всегда, даже если вы точно знаете, что вставляемые записи являются новыми.
#Содержание
Независимые РС. Режим 2. Запись без замещения.
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);Генерируемые запросы:
2.1. Открываем транзакцию
BEGIN TRANSACTION
2.2. Создаем временную таблицу той же структуры, что и регистр.
CREATE TABLE #tt1(_Fld289 NVARCHAR(10), _Fld290 NVARCHAR(10), _Fld291 NVARCHAR(10), _Fld292 NVARCHAR(10), _Fld293 NVARCHAR(10))
временная таблица однотипной структуры создается только однажды в рамках одного и того же соединения с СУБД. Проще говоря, если пользователь записывает тот же регистр второй и более раз, то создание временной таблицы у него будет только при первой записи
2.3. Вставляем строку регистра во временную таблицу.
INSERT INTO #tt1(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей.
2.4. Проверяем, есть ли в таблице записи с таким же набором измерений
SELECT
T1._Fld289
T1._Fld290
T1._Fld291
T1._Fld292
T1._Fld293
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg288 T2
ON T1._Fld289 = T2._Fld289 AND T1._Fld290 = T2._Fld290 AND T1._Fld291 = T2._Fld291
если запрос не пустой — выдаем ошибку. Для периодического регистра в условия соединения таблиц добавляется условие по полю _Period.
2.5. Вставляем данные из временной таблицы в таблицу регистра
INSERT INTO dbo._InfoRg288(_Fld289, _Fld290, _Fld291, _Fld292, _Fld293) SELECT
T1._Fld289
T1._Fld290
T1._Fld291
T1._Fld292
T1._Fld293
FROM #tt1 T1 WITH(NOLOCK)
2.6. Фиксируем транзакцию
COMMIT TRANSACTION
2.7. Очищаем временную таблицу. Обращаю внимание, что вспомогательную таблицу 8.3 очищает вне транзакции, что логично.
TRUNCATE TABLE #tt1
Сразу скажу про отличия с 8.2 — запросы пунктов 2.6 и 2.7 поменяны местами, т.е. в 8.2 сначала очищаем временную таблицу и только затем фиксируем транзакцию. Повторюсь, поведение 8.3 выглядит более логичным. Так же 8.2 дополнительно, после пункта 2.2, выполняет еще один запрос примерно такого содержания:
INSERT INTO #tt1 SELECT * FROM _InfoRg288 T1 WHERE 1=0
этакая пробная вставка, честно говоря, сложно определить его точное назначение, возможно для совместимости, возможно проверка каких-то прав, установка блокировок.
Итак, очевидно, что запись без замещения содержит больше запросов и будет проигрывать записи с замещением. Тут нет подводных камней, просто используйте режимы по прямому назначению, если при записи набора надо к уже существующим данным добавить новые строки, то Записать(ЛОЖЬ), если записать новый или перезаписать целиком существующий набор записей, то Записать().
Вопрос, что делать, если при вставке новых записей хочется убрать все лишние запросы и заставить 1С только вставлять записи? Для этого есть хитрый режим, который появился только в 8.2.19 и 8.3.
#Содержание
Независимые РС. Режим 3. Запись без проверок.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);Генерируемые запросы:
3.1. Открываем транзакцию
BEGIN TRANSACTION
3.2. Вставляем запись в таблицу.
INSERT INTO dbo._InfoRg288(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей
3.3. Фиксируем транзакцию
COMMIT TRANSACTION
Этот режим является самым быстрым для заливки новых данных, но его сфера применения ограничена — логика кода и архитектура решения должна гарантировать, что записываемые данные являются уникальными. При попытке записать дублирующие строки ошибка все равно будет, но уже от самой СУБД:

Выше приведены запросы для непериодического регистра, но отличия от периодического, не содержащего итогов, минимальны — в запросах перед полям измерений добавляется поле _Period, логика и структура запросов, при этом, ровно такая же.
#Содержание
Менеджер записи.
Да, чуть не забыл про менеджер записи регистра сведений. Первое отличие — у менеджера нет свойства ОбменДанными, следовательно, записать в режиме загрузки с его использованием не выйдет. Отличия в запросах СУБД тут появляются только при определенных обстоятельствах. Для случая простой записи данных, например:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Измерение2 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Измерение3 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Записать(Замещать);поведение платформы будет ровно такое же. Оно изменится в следующем случае:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
МенеджерЗаписи.Измерение3 = "Измерение3";
МенеджерЗаписи.Прочитать();
Если МенеджерЗаписи.Выбран() Тогда
// тогда будет отличаться от записи набора записей
Иначе
// записи не существует, а значит
// ранее установленные значения измерений "сбросились"
// поэтому необходимо установить их заново
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
КонецЕсли;
// меняем значение измерения
МенеджерЗаписи.Измерение3 = "Измерение4";
МенеджерЗаписи.Записать(Замещать);и при условии, что прочитанные данные существуют. Фактически мы изменяем существующее значение измерения в записи. При этом платформа добавляет запрос (сразу после начала транзакции) на удаление старых данных:
DELETE FROM T1 FROM dbo._InfoRg288T1 WHERE T1._Fld289=‘Измерение1′ AND T1._Fld290=‘Измерение2′ AND T1._Fld291=‘Измерение3′
Обращаю внимание еще на одну особенность, при чтении, если значение какого либо измерения не указано, то отбор устанавливается по пустому значению этого типа данных:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
// Измерение3 не указываем
МенеджерЗаписи.Прочитать();выполняется примерно следующий запрос:
SELECT * FROM dbo._InfoRg288T1 WHERE T1._Fld289=‘Измерение1′ AND T1._Fld290=‘Измерение2′ AND T1._Fld291=»
все логично — конкретная запись однозначно характеризуется комбинацией значений всех измерений (в том числе периода для периодического регистра), следовательно, хотите прочитать одну запись — укажите значения всех этих «характеристик».
Для себя определился только с одной областью применения — изменять значение измерения у конкретной записи. Подытожу цитатой с ИТС:
…Таким образом, основное назначение менеджера записи — обеспечить без дополнительных сложностей редактирование отдельных записей в интерактивных режимах. С точки зрения производительности использование наборов записей будет максимально эффективным. Использование менеджера записей в некоторых случаях будет столь же эффективным, а в некоторых менее, так как будут выполняться лишние действия.
#Содержание
Тест 2. Подчиненные регистры сведений.
Структура регистра:
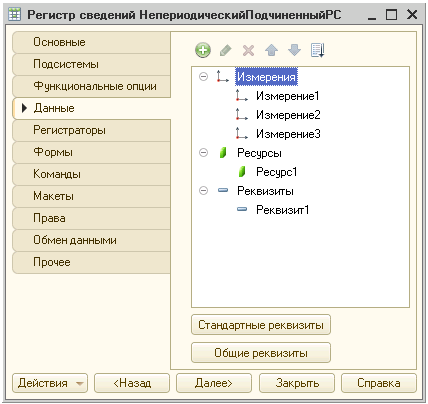

Исполняемый код:
ОбъектРегистр = РегистрыСведений.НепериодическийПодчиненныйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
Регистратор = Документы.Тест.ПолучитьСсылку(Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Регистратор.Установить(Регистратор);
Запись = ОбъектРегистр.Добавить();
Запись.Регистратор = Регистратор;
Запись.Период = ТекущаяДата();
Запись.Измерение1 = Новый УникальныйИдентификатор;
Запись.Измерение2 = Новый УникальныйИдентификатор;
Запись.Измерение3 = Новый УникальныйИдентификатор;
ОбъектРегистр.Записать(Замещать); Подчиненные РС. Режим 1. Запись «по умолчанию».
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ИСТИНА);Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Читаем 100 000 плюс одну запись регистра
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
запрос выполняется только для управляемого режима блокировок. Судя по всему, запрос используется для установки управляемых блокировок по значению измерений и определения надо ли делать эскалацию блокировок. В 8.2 запрос меняется на «SELECT TOP 20001…» и добавляется явно ненужная сортировка по номеру строки «ORDER BY T1._LineNo DESC«.
1.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg301 T1 WHERE T1._RecorderRRef = @P1
1.4. Создаем временную таблицу
CREATE TABLE #tt1(
_RecorderRRef BINARY(16),
_LineNo NUMERIC(9, 0),
_Active BINARY(1),
_Fld302 NVARCHAR(10),
_Fld303 NVARCHAR(10),
_Fld304 NVARCHAR(10),
_Fld305 NVARCHAR(10),
_Fld306 NVARCHAR(10))
напоминаю, что этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД
1.5. Заполняем временную таблицу
INSERT INTO #tt1(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
таких запросов будет столько, сколько строк в записываемом наборе регистра
1.6. Проверка на уникальность по составу измерений.
SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg301 T2
ON T1._Fld302 = T2._Fld302 AND T1._Fld303 = T2._Fld303 AND T1._Fld304 = T2._Fld304
для периодического регистра в условия соединения добавится соединение по полю _Period
1.7. Вставляем записи в таблицу регистра из вспомогательной таблицы
INSERT INTO dbo._InfoRg301(_RecorderRRef, _LineNo, _Active, _Fld302, _Fld303, _Fld304, _Fld305, _Fld306) SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
1.8. Завершение транзакции
COMMIT TRANSACTION
1.9. Очищаем вспомогательную временную таблицу
TRUNCATE TABLE #tt1
#Содержание
Подчиненные РС. Режим 2. Запись с замещением и признаком обмена данными.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ИСТИНА);Генерируемые запросы:
2.1. Открываем транзакцию
BEGIN TRANSACTION
2.2. Для установки управляемой блокировки удаляемых данных читаем 100 000 плюс одну запись регистра (подробно в п. 1.2)
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
2.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg301 T1 WHERE T1._RecorderRRef = @P1
2.4. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg301(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
2.5. Фиксируем транзакцию
COMMIT TRANSACTION
Т.к. это обмен данными, то нет смысла выполнять проверку на уникальность и, как следствие, использовать временную таблицу.
#Содержание
Подчиненные РС. Режим 3. Запись без замещения.
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);Генерируемые запросы:
3.1. Открываем транзакцию
BEGIN TRANSACTION
3.2. Определяем последний существующий номер строки
SELECT TOP 1
T1._LineNo,
T1._Active
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
ORDER BY T1._LineNo DESC
3.3. Читаем 100 000 плюс одну запись регистра
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
только для управляемых блокировок (подробнее чуть выше, в п. 1.2)
3.4. Создаем временную таблицу
CREATE TABLE #tt1(
_RecorderRRef BINARY(16),
_LineNo NUMERIC(9, 0),
_Active BINARY(1),
_Fld302 NVARCHAR(10),
_Fld303 NVARCHAR(10),
_Fld304 NVARCHAR(10),
_Fld305 NVARCHAR(10),
_Fld306 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
3.5. Заполняем временную таблицу нужными данными
INSERT INTO #tt1(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
3.6. Проверка на уникальность
SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg301 T2
ON T1._Fld302 = T2._Fld302 AND T1._Fld303 = T2._Fld303 AND T1._Fld304 = T2._Fld304
для периодического регистра в условия соединения добавится соединение по полю _Period
3.7. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg301(_RecorderRRef, _LineNo, _Active, _Fld302, _Fld303, _Fld304, _Fld305, _Fld306) SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
3.8. Фиксируем транзакцию
COMMIT TRANSACTION
3.9. Очищаем вспомогательную временную таблицу
TRUNCATE TABLE #tt1
#Содержание
Подчиненные РС. Запись без замещения с признаком обмена данных.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);вынужден расстроить, так не работает:

Режим 4. Подчиненный РС с периодичностью по позиции регистратора.

Периодические подчиненные регистры рассматривать отдельно смысла нет — совсем чуть-чуть меняются запросы пунктов 1.6 и 3.6 в части соединения двух таблиц — добавляется условие соединения по полю _Period. Но периодичность по позиции регистратора изменяет логику т.к. уникальность набора записей, дэ-факто, определяется и значениями измерений и значением регистратора и делать проверку из 1.6 нет смысла.
Исполняемый код остается тем же, нас интересует режим записи с замещением (запись по умолчанию).
// (!)Режим загрузки при замещении не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <ЛЮБОЙ>;
// ...
ОбъектРегистр.Записать(ИСТИНА);Генерируемые запросы:
4.1. Открываем транзакцию
BEGIN TRANSACTION
4.2. Для установки управляемой блокировки удаляемых данных читаем 100 000 плюс одну запись регистра (подробно в п. 1.2)
SELECT TOP 100001
T1._Active,
T1._Fld283,
T1._Fld284,
T1._Fld285
FROM dbo._InfoRg282 T1
WHERE T1._RecorderRRef = @P1
4.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg282 T1 WHERE T1._RecorderRRef = @P1
4.4. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg282(_RecorderRRef,_LineNo,_Active,_Fld283,_Fld284,_Fld285,_Fld286,_Fld287) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
4.5. Фиксируем транзакцию
COMMIT TRANSACTION
Запись этого регистра с замещением
ОбъектРегистр.Записать(ЛОЖЬ);будет ровно такой же, как в пункте 3. (Подчиненные РС. Режим 3. Запись без замещения.)
Разбираемся в нюансах. Пример: у вас есть документ с табличной частью из 50 000 строк и при проведении вся таб часть помещается в подчиненный регистр сведений. После перехода с 8.2 на 8.3 этот документ будет дольше перепроводиться за счет того, что платформа будет читать все его старые движения (запрос «..SELECT TOP 100001..»). В то же время, перепроведение этого документа в 8.2 хоть и будет быстрее, но вызовет эскалацию управляемой блокировки на весь регистр и никто другой в это время не сможет его (регистр) изменять. В 8.3 эскалации не произойдет и можно параллельно перепроводить другие документы, изменяющие данные регистра. Аналогичное сравнение и с режимом блокировок — в управляемом режиме (на платформе 8.3) документ будет дольше перепроводиться, но будет возможна многопользовательская работа с этим регистром, а в автоматическом режиме блокировок перепроводиться док будет быстрее, но работать сможет только один пользователь из-за эскалаций блокировок уже на уровне СУБД.
Для этого примера интересным решением будет использовать независимый регистр сведений с индексированным реквизитом ДокументДвижение, используя его как аналог Регистратора. В этом случае можно будет получить профит при записи регистра.
#Содержание
Тест 3. Регистры сведений с итогами.
В 8.3 появилась возможность создать таблицу итогов для периодического регистра, максимально это две таблицы — итоги для среза первых и среза последних. Разработчик сам решает нужны ли ему итоги и какие. По сути, таблица итогов для одной комбинации значений измерений содержит только одну запись (либо самую первую либо самую последнюю), значительно ускоряя получение среза запросом. Но какой ценой нам обходится поддержание этих данных в актуальном состоянии? Для этого посмотрим трассы СУБД в момент записи регистра сведений.
Для экспериментов возьмем периодический независимый регистр с уже известной структурой и установим свойство «Разрешить итоги: срез последних»
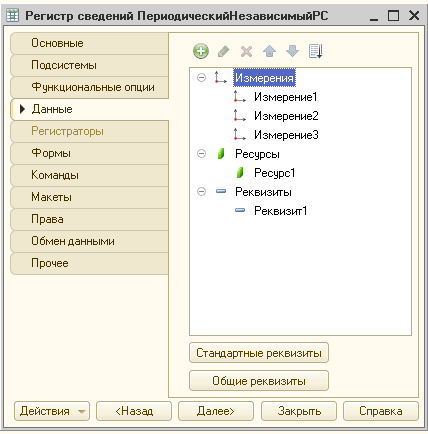

После реструктуризации, в SQL мы получим 3 таблицы:
_InfoRg276 — основная таблица, содержит все записи регистра.
_InfoRgSL296 — таблица итогов, в данном случае срез последних, для среза первых имя таблицы будет содержать «_InfoRgSF…». Очевидно, логика наименования от английских First и Last.
_InfoRgOpt297 — таблица настроек, хранит флаг отключены или нет итоги. Создается своя для каждой таблицы среза.
Исполняемый код:
ОбъектРегистр = РегистрыСведений.ПериодическийНезависимыйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
СтруктураОтбора = Новый Структура();
СтруктураОтбора.Вставить("Период" , ТекущаяДата());
СтруктураОтбора.Вставить("Измерение1", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение2", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение3", Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Период.Установить(СтруктураОтбора.Период);
ОбъектРегистр.Отбор.Измерение1.Установить(СтруктураОтбора.Измерение1);
ОбъектРегистр.Отбор.Измерение2.Установить(СтруктураОтбора.Измерение2);
ОбъектРегистр.Отбор.Измерение3.Установить(СтруктураОтбора.Измерение3);
ЗаполнитьЗначенияСвойств(ОбъектРегистр.Добавить(), СтруктураОтбора);
ОбъектРегистр.Записать(Замещать);Периодические регистры с таблицей итогов. Режим 1. Запись с замещением.
// (!)при записи с замещением режим загрузки не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <ЛЮБОЙ>;
// ...
ОбъектРегистр.Записать(ИСТИНА);Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Читаем настройки регистра.
SELECT T1._SliceUsing FROM dbo._InfoRgOpt297 T1
определяем отключены итоги или нет
1.3. Создаем временную таблицу для сохранения текущих итогов
CREATE TABLE #tt1(
_Period DATETIME,
_Fld277 NVARCHAR(10),
_Fld278 NVARCHAR(10),
_Fld279 NVARCHAR(10),
_Fld280 NVARCHAR(10),
_Fld281 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
1.4. Сохраняем данные из таблицы итогов
INSERT INTO #tt1 WITH(TABLOCK)(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T1._Period,
T1._Fld277,
T1._Fld278,
T1._Fld279,
T1._Fld280,
T1._Fld281
FROM dbo._InfoRgSL296 T1
INNER JOIN dbo._InfoRg276 T2
ON T2._Fld277 = T1._Fld277 AND T2._Fld278 = T1._Fld278 AND T2._Fld279 = T1._Fld279
WHERE T2._Period = @P1 AND T2._Fld277 = @P2 AND T2._Fld278 = @P3 AND T2._Fld279 = @P4
состав условия WHERE зависит от того, какие отборы установлены в записываемом наборе
1.4а. Если запрос выше не пустой, то выполняется удаление считанных данных
DELETE FROM T1
FROM dbo._InfoRgSL296T1
INNER JOIN dbo._InfoRg276T2
ON T2._Fld277=T1._Fld277 AND T2._Fld278=T1._Fld278 AND T2._Fld279=T1._Fld279
WHERE
(T2._Period=@P1 AND
T2._Fld277=@P2 AND
T2._Fld278=@P3 AND
T2._Fld279=@P4)
AND(T2._Fld277=T1._Fld277 AND
T2._Fld278=T1._Fld278 AND
T2._Fld279=T1._Fld279)
состав условия WHERE в первых скобках зависит от того, какие отборы установлены в записываемом наборе
Условие во вторых скобках выглядит избыточным т.к. оно дублирует условие внутреннего соединения таблиц.
1.5. Удаляем старые записи в регистре
DELETE FROM T1 FROM dbo._InfoRg276 T1 WHERE T1._Period = @P1 AND T1._Fld277 = @P2 AND T1._Fld278 = @P3 AND T1._Fld279 = @P4
состав условия WHERE зависит от того, какие отборы установлены в записываемом наборе
1.6. Создаем временную таблицу для записи данных в регистр
CREATE TABLE #tt2(
_Period DATETIME,
_Fld277 NVARCHAR(10),
_Fld278 NVARCHAR(10),
_Fld279 NVARCHAR(10),
_Fld280 NVARCHAR(10),
_Fld281 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
1.7. Добавляем данные во вспомогательную таблицу
INSERT INTO #tt2(_Period,_Fld277,_Fld278,_Fld279,_Fld280,_Fld281) VALUES(@P1,@P2,@P3,@P4,@P5,@P6)
таких запросов будет столько, сколько строк в записываемом наборе
1.8. Вставляем данные в регистр из вспомогательной таблицы
INSERT INTO dbo._InfoRg276(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T1._Period,
T1._Fld277,
T1._Fld278,
T1._Fld279,
T1._Fld280,
T1._Fld281
FROM #tt2 T1 WITH(NOLOCK)
1.9. Обновляем существующие данные в таблице итогов
UPDATE T6 SET _Period = T1.Period_, _Fld280 = T1.Fld280_, _Fld281 = T1.Fld281_
FROM
(SELECT
T5._Period AS Period_,
T5._Fld277 AS Fld277_,
T5._Fld278 AS Fld278_,
T5._Fld279 AS Fld279_,
T5._Fld280 AS Fld280_,
T5._Fld281 AS Fld281_
FROM
(SELECT
T3._Fld277 AS Fld277_,
T3._Fld278 AS Fld278_,
T3._Fld279 AS Fld279_,
MAX(T3._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T3
INNER JOIN #tt2 T4 WITH(NOLOCK)
ON T3._Fld277 = T4._Fld277 AND T3._Fld278 = T4._Fld278 AND T3._Fld279 = T4._Fld279
GROUP BY
T3._Fld277,
T3._Fld278,
T3._Fld279) T2
LEFT OUTER JOIN dbo._InfoRg276 T5
ON T5._Fld277 = T2.Fld277_ AND T5._Fld278 = T2.Fld278_ AND T5._Fld279 = T2.Fld279_ AND T5._Period = T2.MINMAX_PERIOD_) T1
INNER JOIN dbo._InfoRgSL296 T6
ON T6._Fld277 = T1.Fld277_ AND T6._Fld278 = T1.Fld278_ AND T6._Fld279 = T1.Fld279_
WHERE T6._Period < T1.Period_
в запросе вычисляется срез (в данном случае срез последних) и если период нового среза больше периода в таблице итогов, то обновляем значения периода, ресурсов и реквизитов.
Практический пример — добавили свежий курс валюты, соответственно этот запрос обновит значение период, курс и кратность в таблице среза.
1.10. Вставляем в таблицу среза те строки, по которым ранее не было итогов.
INSERT INTO dbo._InfoRgSL296(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T5._Period,
T5._Fld277,
T5._Fld278,
T5._Fld279,
T5._Fld280,
T5._Fld281
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
MAX(T2._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T2
INNER JOIN #tt2 T3 WITH(NOLOCK)
ON T2._Fld277 = T3._Fld277 AND T2._Fld278 = T3._Fld278 AND T2._Fld279 = T3._Fld279
WHERE
NOT(EXISTS
(SELECT
1.0
FROM dbo._InfoRgSL296 T4
WHERE
T3._Fld277 = T4._Fld277
AND T3._Fld278 = T4._Fld278
AND T3._Fld279 = T4._Fld279))
GROUP BY
T2._Fld277,
T2._Fld278,
T2._Fld279) T1
LEFT OUTER JOIN dbo._InfoRg276 T5
ON T5._Fld277 = T1.Fld277_ AND T5._Fld278 = T1.Fld278_ AND T5._Fld279 = T1.Fld279_ AND T5._Period = T1.MINMAX_PERIOD_
если итоги по этим измерениям уже есть, причем не зависимо от значения периода, то строки не добавляем.
Практический пример — для новой валюты добавили первую запись в регистр курсы валют.
1.11. Добавляем не достающие итоги, которые могут появиться при удалении данных.
INSERT INTO dbo._InfoRgSL296(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T4._Period,
T4._Fld277,
T4._Fld278,
T4._Fld279,
T4._Fld280,
T4._Fld281
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
MAX(T2._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T2
INNER JOIN #tt1 T3 WITH(NOLOCK)
ON T3._Fld277 = T2._Fld277 AND T3._Fld278 = T2._Fld278 AND T3._Fld279 = T2._Fld279
GROUP BY
T2._Fld277,
T2._Fld278,
T2._Fld279) T1
LEFT OUTER JOIN dbo._InfoRg276 T4
ON T4._Fld277 = T1.Fld277_ AND T4._Fld278 = T1.Fld278_ AND T4._Fld279 = T1.Fld279_ AND T4._Period = T1.MINMAX_PERIOD_
WHERE
NOT(EXISTS
(SELECT
1.0
FROM dbo._InfoRgSL296 T5
WHERE
T5._Fld277 = T4._Fld277
AND T5._Fld278 = T4._Fld278
AND T5._Fld279 = T4._Fld279
AND(T5._Period >= T4._Period)))
практический пример — удалили последнюю запись курса валюты. В этом случае актуальная запись среза удалится запросом 1.4а, в тоже время таблица #tt2 будет пуста и предыдущий запрос (п.1.10) итогов не добавит, поэтому выполняем отдельную вставку.
1.12. Очищаем вспомогательную таблицу
TRUNCATE TABLE #tt1
1.13. Фиксируем транзакцию
COMMIT TRANSACTION
1.14. Очищаем вспомогательную таблицу
TRUNCATE TABLE #tt2
Для таблицы итогов среза первых выполняются запросы, похожие на 1.3, 1.4, 1.4а и 1.9 — 1.12, отличия только в том, что вместо MAX(T…_Period) будет MIN(T…_Period), а в 1.9 и 1.11 инвертируются условия больше-меньше для поля _Period. Приводить их не стану, думаю логика процесса понятна.
#Содержание
Периодические регистры с таблицей итогов. Режим 2. Запись без замещения.
ОбъектРегистр.Записать(ЛОЖЬ);В полной трассе нет ничего нового, логика аналогична записи без замещения независимого регистра, плюс добавляются запросы по расчету таблицы итогов из трассы выше, это 1.9 и 1.10.
Подчиненные регистры с таблицей итогов.
При исследовании была найдена ошибка записи подчиненных регистров с итогами. Они просто не записываются, причем не в 8.2, ни в 8.3. Появляются такие ошибки:
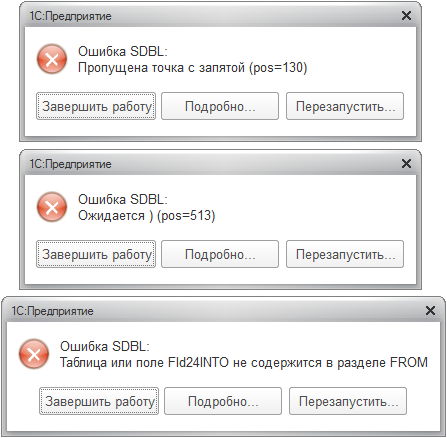
Ошибка зарегистрирована в 1С (клик):

Еще одна полезность данного исследования. Статью обещаю дополнить, как выйдет релиз с исправлением.
Выводы по регистрам с итогами. Начну с отличий от регистров накопления. В таблице итогов регистров сведений, по комбинации значений измерений, всегда хранится только одна — самая актуальная запись. В регистрах накопления итоги хранятся помесячно + текущие итоги. Таким образом, таблица среза будет меньше таблицы остатков, но зато таблицу остатков можно использовать при получении данных за прошлые периоды, а использовать таблицу среза для получения, например, актуального курса валюты на начало прошлого месяца уже не получится.
Второй и очевидный момент — поддержание таблицы среза в актуальном состоянии штука не бесплатная и стоит осознавать, что поток запросов увеличится. Сами по себе запросы потребляют мало ресурсов и выполняются быстро, но количество рано или поздно переходит в качество. Поэтому, если ваш документ записывает с десяток регистров сведений и у каждого из них вы включите обе таблицы итогов, то закономерно ожидать увеличения общего времени проведения документа. Если таких документов проводится много, либо большим числом пользователей, то есть риск заметного увеличения утилизации процессора и на сервере СУБД и на сервере 1С.
#Содержание
3. Как работает СрезПоследних (СрезПервых) в запросе
Чаще всего, когда создается периодический регистр сведений, подразумевается, что получать из него мы будем не все записи, а только одну — самую актуальную. Для этого используется конструкция СрезПоследних, реже — СрезПервых.
Итак, возьмем из примера выше уже известный периодический, независимый регистр с периодичностью «В пределах секунды» и разрешёнными итогами для среза последних.
Исполняемый код:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(
| &ТекущаяДата,
| Измерение1 = ""А""
| И Измерение2 = ""Б""
| И Измерение3 = ""В"") КАК ПериодическийНезависимыйРССрезПоследних";
Запрос.УстановитьПараметр("ТекущаяДата", ТекущаяДата());
Запрос.Выполнить();и посмотрим какой на самом деле формируется запрос в СУБД:
SELECT
T1.Fld277_,
T1.Fld278_,
T1.Fld279_,
T1.Fld280_
FROM
(SELECT
T4._Fld277 AS Fld277_,
T4._Fld278 AS Fld278_,
T4._Fld279 AS Fld279_,
T4._Fld280 AS Fld280_
FROM
(SELECT
T3._Fld277 AS Fld277_,
T3._Fld278 AS Fld278_,
T3._Fld279 AS Fld279_,
MAX(T3._Period) AS MAXPERIOD_
FROM dbo._InfoRg276 T3
WHERE T3._Period <= @P1 AND((((T3._Fld277 = @P2) AND(T3._Fld278 = @P3)) AND(T3._Fld279 = @P4)))
GROUP BY
T3._Fld277,
T3._Fld278,
T3._Fld279
) T2
INNER JOIN dbo._InfoRg276 T4
ON T2.Fld277_ = T4._Fld277
AND T2.Fld278_ = T4._Fld278
AND T2.Fld279_ = T4._Fld279
AND T2.MAXPERIOD_ = T4._Period
) T1
Запрос использует таблицу _InfoRg276 — это непосредственно наш регистр сведений ПериодическийНезависимыйРС. Вопрос «Где наша таблица итогов» оставим на вкусное, а пока давайте разберемся с этой конструкцией т.к. именно она будет использоваться чаще всего. А в 8.2 без вариантов — только так и работает.
Так как в запросе участвует одна таблица — непосредственно наш регистр, то логику запроса СУБД можно воспроизвести в запросе 1С.
Аналог конструкции СрезПоследних() на языке 1С для регистра с периодичность НЕ равной «По позиции регистратора»:
ВЫБРАТЬ
Т1.Измерение1,
Т1.Измерение2,
Т1.Измерение3,
Т1.Ресурс1
ИЗ
(ВЫБРАТЬ
Т4.Измерение1 КАК Измерение1,
Т4.Измерение2 КАК Измерение2,
Т4.Измерение3 КАК Измерение3,
Т4.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
Т3.Измерение1 КАК Измерение1,
Т3.Измерение2 КАК Измерение2,
Т3.Измерение3 КАК Измерение3,
МАКСИМУМ(Т3.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийНезависимыйРС КАК Т3
ГДЕ
Т3.Период <= &ТекущаяДата
И Т3.Измерение1 = «А»
И Т3.Измерение2 = «Б»
И Т3.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
Т3.Измерение1,
Т3.Измерение2,
Т3.Измерение3) КАК Т2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийНезависимыйРС КАК Т4
ПО Т2.Измерение1 = Т4.Измерение1
И Т2.Измерение2 = Т4.Измерение2
И Т2.Измерение3 = Т4.Измерение3
И Т2.MAXPERIOD_ = Т4.Период) КАК Т1
Повторюсь, это абсолютно тот же запрос, что выполнился в СУБД, более того, он полностью рабочий и будет возвращать идентичный результат. Тут отчетливо видна логика, по которой делается «срез» и то, что запрос имеет два уровня вложенности.
#Содержание
Аналог конструкции СрезПоследних() на языке 1С для регистра с периодичность «По позиции регистратора»:
ВЫБРАТЬ
T1.Измерение1,
T1.Измерение2,
T1.Измерение3,
T1.Ресурс1
ИЗ
(ВЫБРАТЬ
T6.Измерение1 КАК Измерение1,
T6.Измерение2 КАК Измерение2,
T6.Измерение3 КАК Измерение3,
T6.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
T3.Измерение1 КАК Измерение1,
T3.Измерение2 КАК Измерение2,
T3.Измерение3 КАК Измерение3,
T3.MAXPERIOD_ КАК MAXPERIOD_,
МАКСИМУМ(T5.Регистратор) КАК MAXRECORDERRRef
ИЗ
(ВЫБРАТЬ
T4.Измерение1 КАК Измерение1,
T4.Измерение2 КАК Измерение2,
T4.Измерение3 КАК Измерение3,
МАКСИМУМ(T4.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T4
ГДЕ
T4.Период <= &ТекущаяДата
И T4.Измерение1 = «А»
И T4.Измерение2 = «Б»
И T4.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
T4.Измерение1,
T4.Измерение2,
T4.Измерение3) КАК T3
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T5
ПО T3.Измерение1 = T5.Измерение1
И T3.Измерение2 = T5.Измерение2
И T3.Измерение3 = T5.Измерение3
И T3.MAXPERIOD_ = T5.Период
ГДЕ
T5.Измерение1 = «А»
И T5.Измерение2 = «Б»
И T5.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
T3.Измерение1,
T3.Измерение2,
T3.Измерение3,
T3.MAXPERIOD_) КАК T2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T6
ПО T2.Измерение1 = T6.Измерение1
И T2.Измерение2 = T6.Измерение2
И T2.Измерение3 = T6.Измерение3
И T2.MAXPERIOD_ = T6.Период
И T2.MAXRECORDERRRef = T6.Регистратор) КАК T1
Периодичность по позиции регистратора подразумевает, что в одну и ту же секунду может быть несколько записей с одинаковым значением измерений, поэтому одной группировки с расчетом максимального периода не достаточно, необходимо сделать еще одну, вычисляя максимальный регистратор. Запрос имеет уже 3 уровня вложенности и является более сложным для оптимизатора СУБД, как следствие, больше рисков получить не оптимальный план запроса.
#Содержание
Давайте рассмотрим самую частую ошибку при работе с виртуальными таблицами — перенесем фильтры в условие ГДЕ:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(&ТекущаяДата, ) КАК ПериодическийНезависимыйРССрезПоследних
|ГДЕ
//!!! это ошибка !!! отборы по измерениям необходимо делать в виртуальной таблице
| ПериодическийНезависимыйРССрезПоследних.Измерение1 = ""А""
| И ПериодическийНезависимыйРССрезПоследних.Измерение2 = ""Б""
| И ПериодическийНезависимыйРССрезПоследних.Измерение3 = ""В""";
Запрос.УстановитьПараметр("ТекущаяДата", ТекущаяДата());
Запрос.Выполнить(); Аналог данного запроса будет выглядеть так:
ВЫБРАТЬ
Т1.Измерение1,
Т1.Измерение2,
Т1.Измерение3,
Т1.Ресурс1
ИЗ
(ВЫБРАТЬ
Т4.Измерение1 КАК Измерение1,
Т4.Измерение2 КАК Измерение2,
Т4.Измерение3 КАК Измерение3,
Т4.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
Т3.Измерение1 КАК Измерение1,
Т3.Измерение2 КАК Измерение2,
Т3.Измерение3 КАК Измерение3,
МАКСИМУМ(Т3.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийНезависимыйРС КАК Т3
ГДЕ
Т3.Период <= &ТекущаяДата
СГРУППИРОВАТЬ ПО
Т3.Измерение1,
Т3.Измерение2,
Т3.Измерение3) КАК Т2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийНезависимыйРС КАК Т4
ПО Т2.Измерение1 = Т4.Измерение1
И Т2.Измерение2 = Т4.Измерение2
И Т2.Измерение3 = Т4.Измерение3
И Т2.MAXPERIOD_ = Т4.Период) КАК Т1
ГДЕ
Т1.Измерение1 = «А»
И Т1.Измерение2 = «Б»
И Т1.Измерение3 = «В»
т.е. в отличие от предыдущего варианта мы сначала выбираем ВСЕ записи регистра с периодом меньше указанной даты, группируем их вычисляя последний период, соединяем с таблицей для получения значений ресурсов и только после этого фильтруем по измерениям. Как результат — мы читаем значительно больше данных, чем требуется.
Справедливости ради стоит отметить, что продвинутые СУБД, в частности MS SQL 2012 и 2014 (на 2005 — 2008 не тестил, но думаю поведение аналогичное) в обоих случаях построят одинаковый план запроса и разницу в скорости выполнения вы не заметите. Но файловая база так не умеет, она будет действовать строго по инструкции — написано выбрать все записи, значит надо выбрать все. И нет, это не значит, что если база на SQL, то можно косячить))
#Содержание
На этом же примере хочу показать влияние структуры индексов на план запроса.
Сравним два плана однотипного запроса, выполненного в 8.2 и в 8.3 (СУБД: SQL 2014), исполняемый код тот же (разумеется рассматриваем вариант без ошибки). Напомню, что для 8.2 кластерным будет индекс [Период + Измерение1 + Измерение2 + Измерение3], а в 8.3: [Измерение1 + Измерение2 + Измерение3 + Период].
План запроса для 8.2:
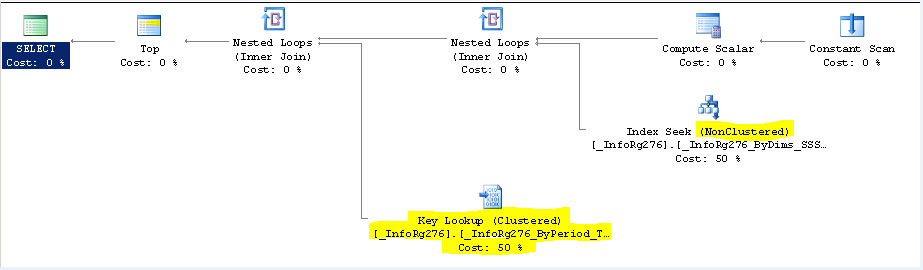
тот же запрос для тех же данных но в 8.3:
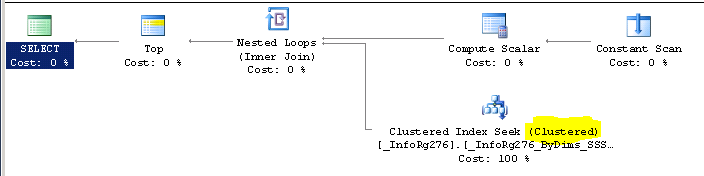
Почему в 8.2 выполняется больше операций? Если рассмотреть условие по периоду «… Т3.Период <= &ТекущаяДата …», то становится понятно, что из-за оператора «меньше или равно» эффективно использовать индекс [Период + Измерение1 + Измерение2 + Измерение3] не получится — под это условие могут попасть вообще все записи регистра, каждую из которых потом придется проверить на соответствие фильтрам по измерениям. Поэтому СУБД выбирает индекс [Измерение1 + Измерение2 + Измерение3 + Период], но т.к. в 8.2 он не кластерный то он не содержит значения ресурсов и реквизитов регистра. Вот за этими значениям и приходится «лезть» в таблицу (читай в кластерный индекс), на плане запросов это операция Key Lookup. Результат — количество прочитанных данных для 8.3 может быть в половину меньше, чем в 8.2.
#Содержание
Давайте вернемся к вопросу, зачем мы делали таблицу итогов, если запрос все равно её не использует, как же так…
Как уже говорил выше, когда разбирались в отличиях итогов регистра накопления и регистра сведений, таблица среза всегда хранит только одну — самую актуальную запись среза. Поэтому, когда 1С «видит» запрос среза на какую то дату /..СрезПоследних(&ТекущаяДата, …) /, то она не использует итоги т.к. не может гарантировать, что в них будет находиться актуальный для этой даты срез. Таблица итогов будет использована только если нужен самый-самый актуальный срез, т.е. если в виртуальной таблице не указан параметр периода:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(
| ,
| Измерение1 = ""А""
| И Измерение2 = ""Б""
| И Измерение3 = ""В"") КАК ПериодическийНезависимыйРССрезПоследних";
Запрос.Выполнить();в этом случае в СУБД увидим такой запрос:
SELECT
T1.Fld277_,
T1.Fld278_,
T1.Fld279_,
T1.Fld280_
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
T2._Fld280 AS Fld280_
FROM dbo._InfoRgSL296 T2
WHERE ((((T2._Fld277 = @P1) AND(T2._Fld278 = @P2)) AND(T2._Fld279 = @P3)))
) T1
Бинго! Вот она, наша таблица итогов — _InfoRgSL296. Видим, что запрос стал гораздо меньше и проще. И его можно сделать еще более эффективным, если индекс таблицы итогов станет кластерным. Будем ждать от 1С этой оптимизации.
Рассмотрим ситуацию, когда число записей в самом регистре очень близко к числу записей в таблице среза. Например, данные в вашем периодическом регистре меняются очень редко и в 90% случаев он содержит только одну запись для уникальных значений измерений, а в остальных 10%: 2-3 записи. В этом случае использование итогов лишено смысла т.к. теряется основной профит — нет сокращения объема читаемых данных.
Выводы:
- Простая конструкция СрезПоследних может легко превратиться в достаточно сложный запрос с двумя, а то и с тремя уровнями вложенности. Это необходимо иметь в виду, особенно при соединении срезов с другими таблицами и вложенными запросами.
- Включение итогов по срезам поможет оптимизировать только те запросы, где срез делается без указания даты /..СрезПоследних(, …)../, в противном случае — напрасные накладные расходы на поддержание актуальности таблиц итогов.
- Периодичность «По позиции регистратора» следует использовать осторожно из-за сложного запроса получения среза. Если согласно закладываемой логике два документа, в одну и ту же секунду, НЕ могут сделать запись с одинаковыми значениями измерений, то использование этой периодичности является избыточным.
Заключение.
Что планировал — рассказал. Надеюсь для вас работа с регистрами сведений станет более прозрачной и эффективной.
Пишите, чем еще можно дополнить исследование, какие моменты раскрыть более детально. Дополняйте статью комментариями о своем опыте и фишках.
Успехов!
#Содержание